
Data preparation for LLMs: techniques, tools and our established pipeline
Let’s explore methods and technologies for maximizing efficiency in data collection and preparation for training large models. I will outline the pipeline in detail and discuss our own chosen workload for dataprep.
Why are datasets for LLMs so challenging? As with any machine learning task, data is half the battle (the other half being model efficiency and infrastructure). Through the data, the model learns about the real world to tackle tasks after deployment. At the training stage, it’s crucial to present the model with diverse and unique texts to demonstrate the world’s vast diversity.
Equally important is how you handle the data, specifically the quality of your data cleaning and the efficiency of your pipeline. Preparing a large dataset can be costly if done inefficiently. In this article, I will walk through stages of collecting and preparing data for training LLMs, the pipeline displayed below. I will cover the infrastructure tools applicable at each stage and our choices for maximizing efficiency and convenience.
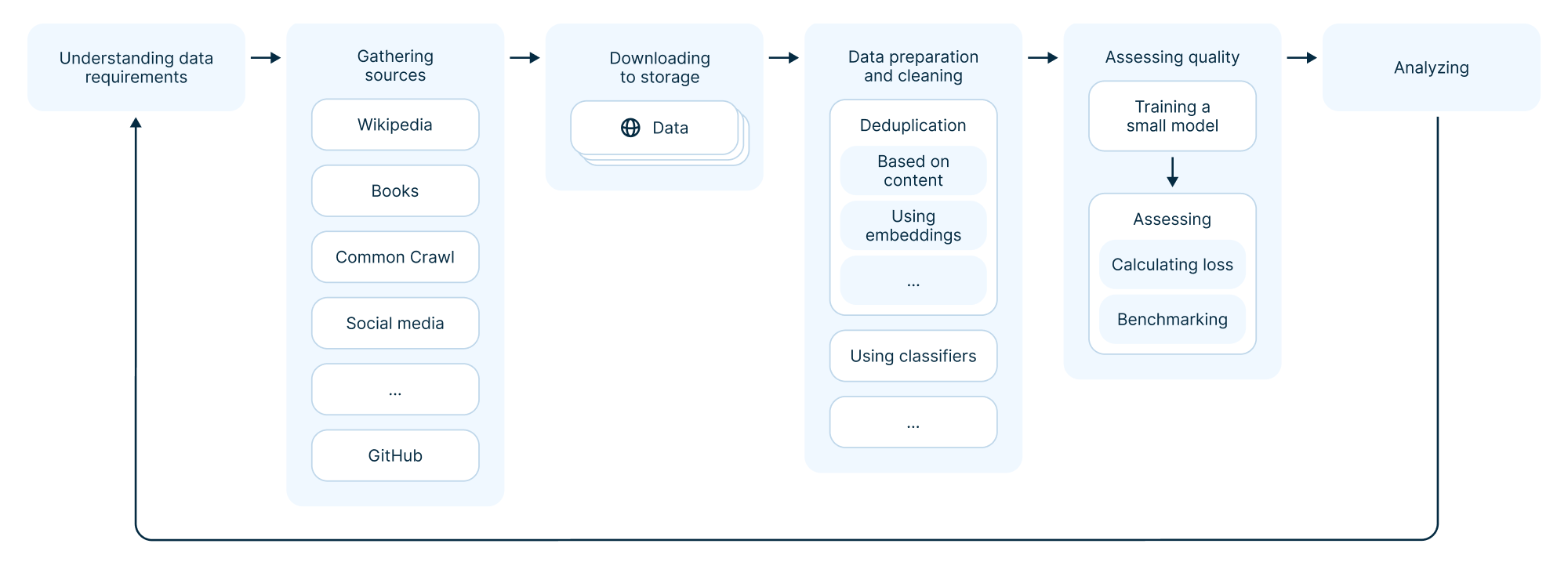
Part 1. Data preparation techniques
Training from scratch vs. fine-tuning
When choosing data preparation methods, first decide whether to train a foundational model from scratch or fine-tune an existing one. In the first scenario, you’re feeding the model a vast amount of general knowledge. However, most opt for the second scenario, where someone has already invested millions to instill basic knowledge in the model using foundational texts. This means you are training a model to solve a specific task within a particular domain: medicine, law, programming, or another field. Therefore, you prepare data that is particularly useful in this area of knowledge. In the second scenario, the dataset size can also be quite large to help the foundational model better adapt to the domain without entirely forgetting common knowledge. This context is essential when discussing dataset collection and preparation.
Selecting data sources for your model
For training, you can use ready-made datasets — those that someone else has collected and made available. You can use them as is or after preprocessing if the license permits.
Hand-curated, error-free datasets are too scarce to train LLMs effectively. One of the last successful examples was BERT, trained on curated data, including Wikipedia and a book corpus. Since then, models have become larger, requiring significantly more data to train. Starting with GPT-2, Common Crawl has been used. Ideally, the quality should be the same, but that’s rarely the case. As a result, Common Crawl — a snapshot of the internet — is often used. It is sufficient for training but of much lower quality. The decision on whether to use Common Crawl or not is, by the way, one of the first you’ve got to make. The reason is that processing content from the entire internet using your own or cloud infrastructure is a resource-intensive task that affects a substantial part of your investments.
How do you determine which sources are needed? One idea is to include code or math, even if generated by another model, to ensure our model learns formal logic. However, these are just ideas.
As a minimum, the dataset should include:
- Wikipedia
- Books/textbooks
- Scientific articles
- News
- Social media/forums
- Legal/government documents
- Code
Essentially, it should include the same types of content that humans read.
Document weighting strategies
If you are not training from scratch but fine-tuning, certain types of sources will have more weight, with weighing usually based on intuition. For instance, Wikipedia data is of such high quality that it often makes sense to repeat it (i.e., repeat the volume of tokens as needed and feed it into the model) several times. Having the model learn this data better won’t hurt, as it contains valuable facts.
There are different ways to apply weights:
- Equally across all documents.
- Proportionally to the number of documents from each source.
- Based on the number of tokens.
- According to a quality metric of the dataset.
- A combination of all the above.
Weights are usually set at the beginning of training to ensure some level of reproducibility. Having said that, specialists usually reweight their sources when composing the final dataset, improving model quality.
Handling multiple languages in datasets
Languages used in texts add another dimension of complexity. By default, models are trained in English due to the abundance of data, research, datasets, and resources available in this language. Training a model in a non-English language presents numerous challenges, including a lack of data, absence of datasets, and sometimes no readily available benchmarks. Essentially, there are neither sufficient data nor means to measure the results.
Benchmarks evaluate the quality of a trained LLM by testing it on specific datasets to see if it generates correct texts from the input, correctly answers questions, chooses the correct answer in a test, writes functional code, and so on. A cost-effective approach widely used today is to train models in English plus a few other necessary languages. Internally, the model translates and draws knowledge from different languages if it lacks sufficient data in the original tongue.
So, as an example of a choice you might want to make during reweighing, you can decide not to take equal portions of all languages but rather 90% English and distribute the remaining percentage among other languages.
Common Crawl and deduplication management
Common Crawl methods are limited in the websites they can visit. The internet index is skewed compared to Google’s because only search engines have click and query data to guide their decisions on which resources to crawl. Thus, creating an internet mirror and building a search engine are two very different tasks.
Another decision is whether to work directly with raw data, such as raw HTML. Depending on your resources, you may want to extract texts yourself or use the results of others' work. Common Crawl can perform extractions, but it is not the best extractor. For certain domains, this can be critical. For instance, if a page contains a lot of code or educational materials, the extractor might turn the page into nonsense. If the data is specific, it might be worth extracting it yourself from HTML, tuning parsers, and so on.
Crawls can repeat themselves because page content can change, and the same URLs can appear in the dataset multiple times. For example, we only take URLs from the freshest crawl and discard duplicate documents. To train a model on up-to-date data, it’s better to use the latest crawl. Crawls are collected regularly and available over long periods, leading to data duplication since the same page can be crawled multiple times, and many pages contain identical content. As you go further back in time, the crawls 'thin out' due to complete text and document duplicates. You have a choice: perform basic data cleaning yourself or use a dataset with pre-cleaned crawls.
In general, if you need to train on fresh data, it’s better to work with raw crawl data to remain independent. This means not waiting several months for someone to process a newer crawl and publish it. If you want to continuously fine-tune using the freshest data, you might want to use your own crawl. It’s not a matter of waiting for a new crawl — someone will always be forming a new dataset based on crawls, including fresh snapshots. You can utilize these:
So, we’ve obtained the texts and deduplicated them by URLs and content. How do we determine what’s trash and what’s a good document?
Data cleaning using Common Crawl as an example
To clean data, you can follow two approaches (either one of them or both simultaneously):
1. 'I understand what trash is and how to detect duplicates, and I want to remove them.' How do we understand what trash is? Various methodologies exist — a set of heuristics that migrate from article to article. You can discard documents that are too short, too long, contain too many numbers, too few letters, too many repeated words, or paragraphs without a period at the end. You can imagine a model that predicts whether a text is useful or similar to Wikipedia content. These features are devised manually by people. Some articles argue that these methods improve certain metrics. But it is not guaranteed to improve the final model quality on your particular task.
2. 'I understand what a good document is.' This is particularly useful when training a specialized model. The simplest approach is to mine useful documents by domain. Usually, you know useful domain-specific sites (e.g., for medicine), and you can take texts only from them. This is one method. Another is by similarity: looking for documents similar to a known good one, like in recommendation systems. You can convert documents into embeddings and find similar ones. You can train a classifier. This task mirrors the one of discarding trash.
There are also more complex techniques — some experts score documents with other models by asking questions like, is this document useful for training an LLM?
For certain sources, you also need to decide how to format them. For example, with Reddit, because Reddit is a graph of articles and comments, you need to determine how to structure this comment tree so the model learns the logical flow of discussion. You also need to filter out NSFW subreddits.
Another idea is to look for inexact duplicates: documents that are not 100% identical but very similar. Many pages have identical content with only a few words changed, often inserted according to a template. These can be found using embeddings or MinHash, a type of embedding that represents text as a vector.
You can analyze on a paragraph level: find documents with many repeated paragraphs, considering them potential duplicates. Another approach is to improve the text extractor from HTML by discarding headers, footers, navigation elements, or other non-meaningful artifacts, leaving only useful paragraphs.
It’s important to distinguish having duplicates in the source texts from reweighting. First, clean out duplicates, then consciously reweight the sources.
Evaluating dataset quality
There’s no benchmark that will tell you, before training begins, whether you’ve prepared a good dataset. This is the primary headache for ML or MLOps engineers responsible for dataset preparation.
The main approach is to collect the dataset, start training a small model, and observe whether a model trained on a slightly different version of the dataset yields different benchmark values. Unfortunately, this method is costly, time-consuming, and offers no guarantees. It’s unknown how results will change with increasing model and dataset sizes.
It is technically possible to cheat by adding to the dataset the exact questions and answers used in benchmarks. Since a model is often just a binary file, no one will catch you red-handed. But here are other ways to optimize models for benchmarks without being so dishonest. For instance, it is also technically possible to search for texts similar to benchmark queries and 'train' the model on them. Our strong opinion, though, is that you should clean out benchmarks to ensure your evaluation tools reflect the real picture. Someone might publish them on the internet, and they could accidentally end up in your dataset.
Another important issue is copyright and its impact on benchmarks. Many benchmarks test the model’s knowledge of school and university curricula. However, many school and university textbooks are copyrighted. Legally, you can’t include them in your dataset — just like most modern books. So, if books do appear in datasets, they are usually very old. There are quite a limited amount of educational materials with open licenses.
Dataset tokenization
When you have a clean and quality text dataset ready, it needs to be tokenized, as the model does not work with texts. Here, you must decide whether to train your own tokenizer. Although such a process is more related to model training than data preparation, let’s briefly discuss it.
You’ve assembled your dataset and defined its composition by sources and languages — now the tokenizer is trained and the data is tokenized. The tokenizer implements your chosen method of encoding text. Various methods exist, the most simple being character-based: assigning an ID to each character and converting the character to a number. This is inefficient compared to other techniques because it makes it difficult for the model to learn anything meaningful — but can be useful in certain contexts, such as dealing with rare words or languages with large vocabularies.
A more common method is word-based encoding. However, there are many words, which directly impacts how well the model can be trained and how many resources it needs. Therefore, an intermediate method exists: using the most frequent sequences of characters for encoding. Essentially, this involves taking a word, for example, without its ending or prefix, leaving the sequence often matching the word’s root (because it is frequent enough) and encoding this sequence. The model learns that a particular root roughly means this or that. This is currently the main method for text encoding.
The tokenizer scans the text, counts the most frequent sequences, and attempts to encode them most efficiently. In practice, this usually means taking a ready-made library, configuring it, and applying it. But there are exceptions; for example, the creators of Llama at Meta wrote their own tokenizer.
Here’s a video guide on how to build a GPT tokenizer. You can learn more about popular tokenization methods (BPE, Wordpiece and Unigram) on Hugging Face.
Upcoming challenges in data preparation
As models become larger, even the vast amount of data from Common Crawl starts to fall short. A well-cleaned dataset from Common Crawl is not significantly larger than other modern datasets, posing a challenge in providing sufficient data for training increasingly large models.
Secondly, after the release of ChatGPT, the internet is increasingly filled with synthetic data. While there is still enough data, the amount of synthetic content is growing rapidly, much like a bubble. This reduces the value of Crawl data for training models.
Thirdly, most written knowledge — books, textbooks, and other educational content — is protected by copyright and cannot be used legally. This limitation is a significant challenge in assembling high-quality datasets for model training.
We’ve discussed the properties a dataset suitable for training a large model should have and the stages we must go through to prepare it. In the second part, we will look at how different teams, including our LLM R&D team, typically approach this process — what infrastructure is required for data preparation and which tools are best to use.
Part 2. Tools and technologies for data preparation
Theoretically, you can perform data preparation on your laptop. You could run a Python script, read a file line by line, and write to a file line by line. For basic LLM-related tasks involving simple fine-tuning on a small model, a modern laptop or cloud VM suffices. The complexity starts when you can’t fit all the data or the entire model into a single machine’s memory or store them on a single disk. My colleague Panu discussed orchestration in a recent article about Slurm vs. Kubernetes.
Typical data preparation workload
Here are the main components of a typical dataprep workload:
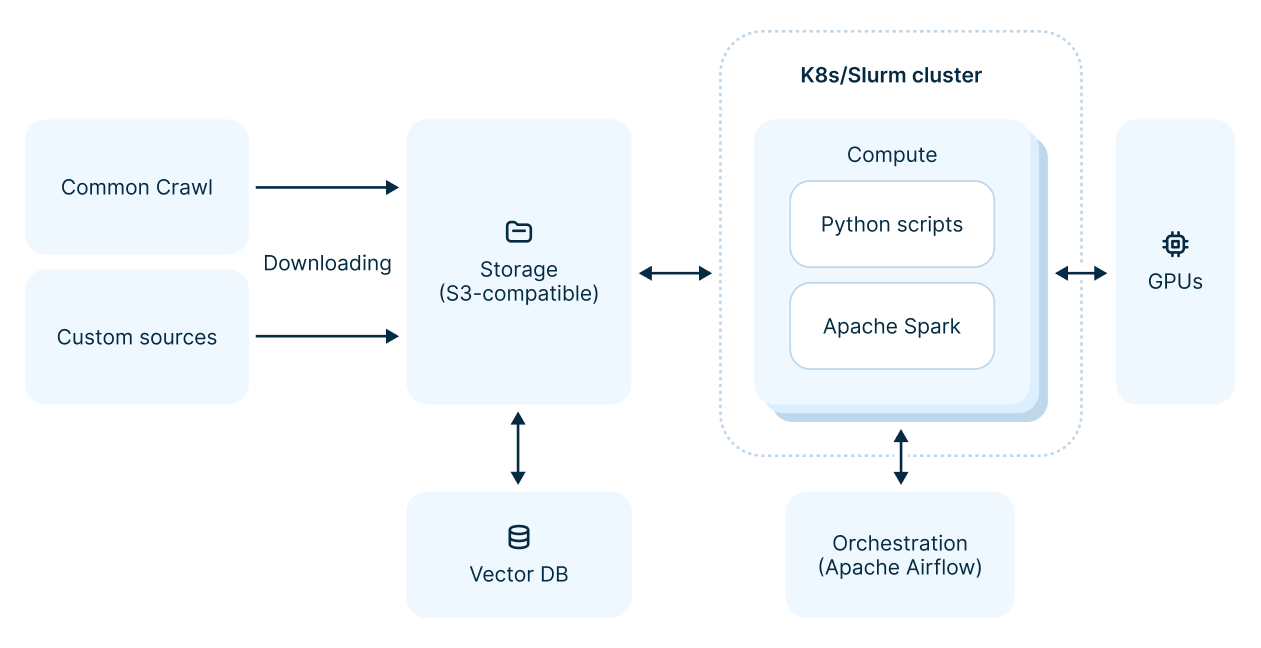
Let’s explore these steps in greater detail.
Downloading and storing data
The first step in working with data is downloading it from the internet to make it available for training data preparation. Why can’t data be read on the fly? It is more reliable to read data from your cloud or network. You need to stream data as reliably as possible and avoid potential losses due to network unavailability, timeouts, and so on.
Network costs arise regardless. Your virtual machines should run in the same cloud as your storage, or you’ll incur charges for transferring large amounts of data, which can be prohibitively expensive. Data for such distributed workloads are stored in 99% of cases in object storage compatible with S3 — simply because it’s easier. Object storage resembles a file system. As for data formats, these could be simple text files or, in a less primitive case, files in the Apache Parquet format.
If considering alternatives to object storages (Hadoop or even local disks), the choice depends on the amount of data, the extent of processing needed, and the available time. Some authors might have processed data for months due to the current infrastructure constraints for such tasks.
A few words about vector databases
In ML, a vector database stores embeddings of entities, searches among them for similarities, and uses this during data preparation — for example, for deduplication or sampling. The simplest approach is storing vectors in a memory database and performing queries. Specialized solutions like Milvus or Qdrant are available but are often overkill for this task.
Data processing engine
Data preparation usually runs on the same computational resources as other LLM workloads. For small projects, this might be a laptop or cloud VM. For larger projects, it’s often Kubernetes. Specialized data engines like Apache Spark are used by experienced users. Many ML engineers write regular Python scripts for processing, running them sequentially and avoiding complex setups. It’s understood that companies use more powerful tools, but this information is not usually public.
Orchestration
The same situation applies to orchestrating training pipelines. For small projects, ML engineers may manage with manual runs or cron jobs. For larger projects with many experiments and pipelines, orchestration uses tools already adopted by the company, ranging from Airflow to ML-specific Kubeflow. Often, custom-built tools are used within the team. These orchestrators run data preparation code in the required sequence and schedule.
ML at the data prep stage
ML models themselves are sometimes used for data preparation. A GPU-powered (or CPU-powered, though slower) model can extract new knowledge from documents: calculate new features, learn new properties, filter data to identify useful documents and filter documents according to score calculated by the model. We’ve discussed trash classifiers or documents similar to educational ones. In one case, delete; in another, mark separately and sample. This way, we find similar documents: take a text, calculate its embedding, store it in a vector database, and search for similar ones, enriching the dataset.
Simplifying the workload with TractoAI
We have discussed the tools used by many teams in the industry and academia. Now let’s move on to the approach of our LLM R&D team. The most important thing is that we use TractoAI, which greatly simplifies data preparation processes. Here’s how the use of TractoAI affected the organization of our data prep workloads:
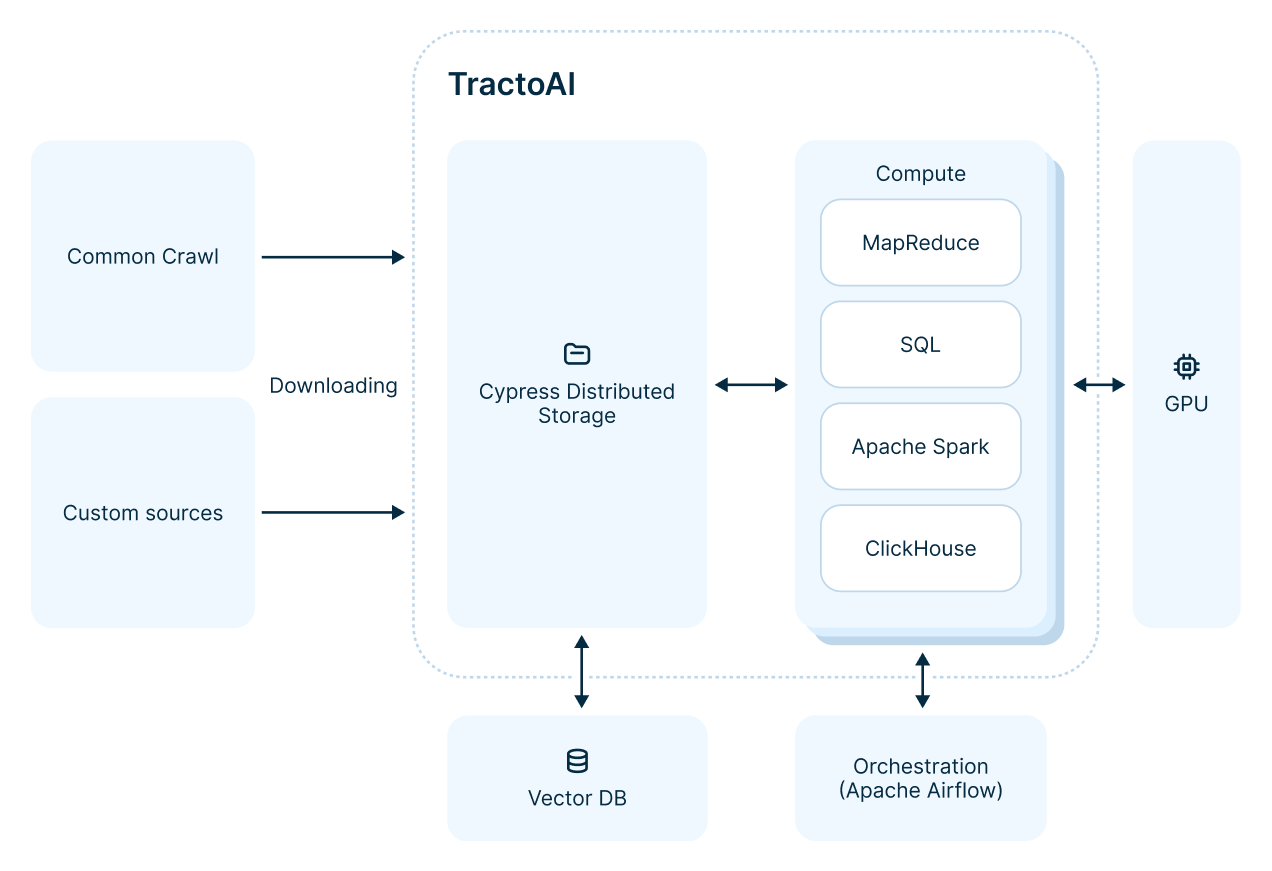
Let’s break the whole pipeline down step by step.
Storing data
The problem with standard S3 approaches is that vast amounts of data can’t be stored as a single file due to size. Splitting the file into parts is a headache. Quite similar to Hadoop + Spark stack set TractoAI handles these issues, ensuring files don’t get too large, don’t get lost, and can be read properly.
In essence, you interact with an abstraction where your data is represented as an SQL-like table, despite the complex machinery within. You don’t need to separate data into files or handle multithreaded reading and writing.
Data processing engine
TractoAI has several engines (SQL, MapReduce, Spark, etc.) for calculations and MapReduce engine solves many problems for us. It can store data, read it in parallel, process it, and ensure consistency. All the main steps we listed would otherwise need to be done manually. If you need hundreds of virtual machines working in parallel, you need MapReduce.
Deduplicating texts from Crawl isn’t always done 'honestly, ' especially without access to MapReduce. Deduplication is often parallelized across several cloud machines, with each machine deduplicating data only within what it receives. This cost-effective method removes only some duplicates — globally, they can still be present. MapReduce performs honest deduplication.
A key feature of MapReduce systems, which Slurm and other orchestrators lack, is the Reduce operation. MapReduce systems can perform distributed sorting, a crucial difference. Sorted data using Slurm requires splitting it into files so keys aren’t divided between files.
Sorting data and then processing it is a sequential process: many files are read line by line, a function is applied to each line, and the data is transformed. In TractoAI terms, this is a Map operation. Grouping data when you have a lot of it can’t be done in a reasonable time without MapReduce. While there are some open-source implementations, MapReduce remains the most efficient. Distributed data sorting and reading sorted data bring us back to the classic MapReduce concept.
Another advantage is that it works equally well with both large and small datasets. You can cheaply test an idea or process a small dataset, then scale it up if necessary without modifying the code.
Working with embeddings
To search for similar documents, it can be useful to calculate their embeddings using a pre-trained model. This can be done as a map operation in TractoAI and efficiently parallelized across many GPUs. The resulting data can then be used for tasks like similarity search or other purposes.
Bonus: Possibility of ad-hoc analysis
TractoAI saves time and labor costs for data analysis. You don’t have to think about it — everything is done for you. There’s an entry point for loading data, and it just works. Additionally, TractoAI has its own SQL-like language. With it, you can view a block of data and quickly calculate something based on it.
In many teams, SQL-driven development is common. For each data operation (dozens of times a day), you switch to SQL or write UDFs in C++. You create another abstraction in the form of SQL over MapReduce, further accelerating the process with minimal effort.
In S3, this would be much more complicated. First, you need to find where the data is stored, then write Python code to read, aggregate, and display it. It takes more time and effort. Without TractoAI or a similar system, this process would involve building libraries specifically for data calculations, but it still wouldn’t be as easy.
As a result, we have numerous methods to preprocess data and compile datasets, and we can conduct many experiments with these datasets. Since we are a research team, this is crucial for us. The more hypotheses we test, the more we learn. Following our enhancements, infrastructure optimization, and the integration of TractoAI, data preparation has ceased to be a bottleneck for us.
Explore Nebius AI
Learn more about TractoAI

Contents
-
Part 1. Data preparation techniques
- Training from scratch vs. fine-tuning
- Selecting data sources for your model
- Document weighting strategies
- Handling multiple languages in datasets
- Common Crawl and duplication management
- Data cleaning using Common Crawl as an example
- Evaluating dataset quality
- Dataset tokenization
- Upcoming challenges