

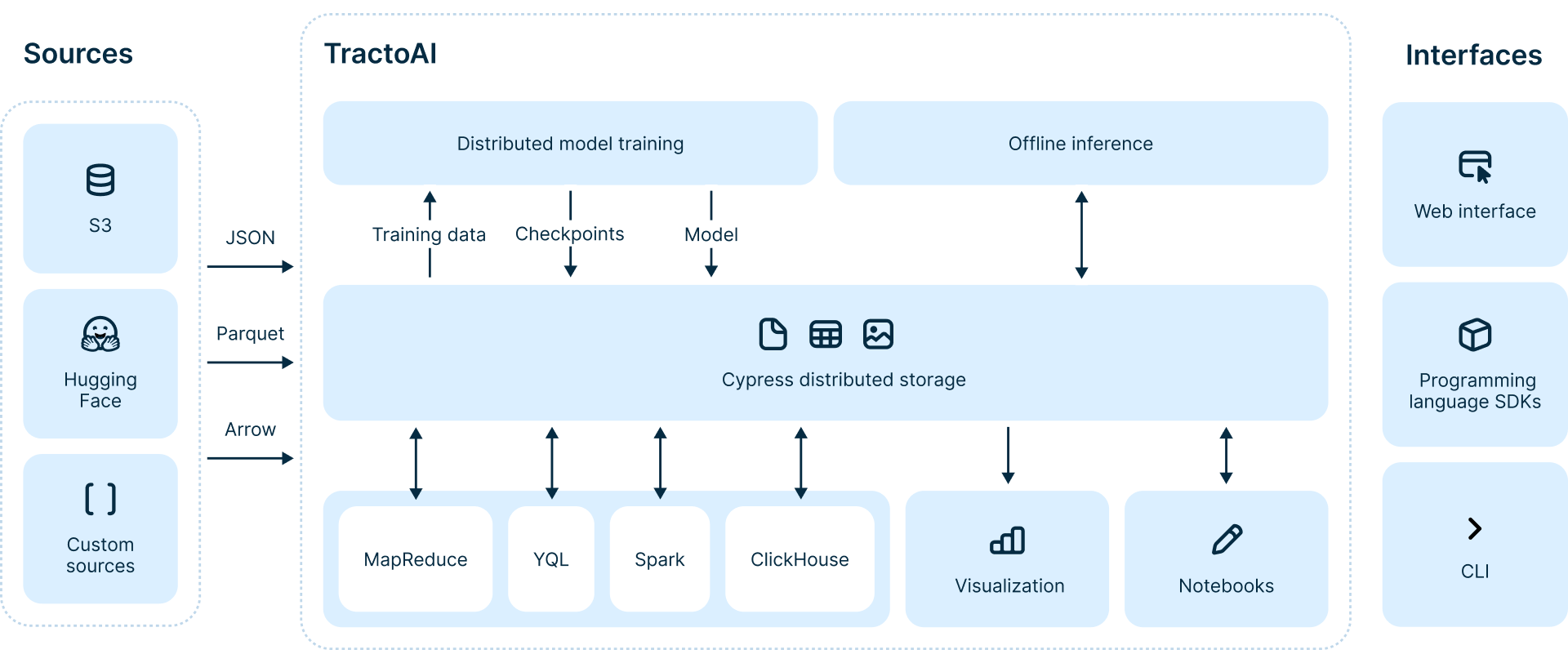


Store your data the way you want it
Upload your data, whether in tables or files, to Cypress, our resilient distributed file storage, for further processing or as a training dataset. Choose between HDD or NVMe storage, select the optimal compression codec and manage older data with erasure.
At its core, the TractoAI engine is built for tables, moving away from loosely structured files. Our tables support trillions of rows, thousands of columns, and petabytes of data of any kind of format (from plane numeric numbers and JSONs to vectors, pictures and videos). Just provide a schema and annotate your datasets in Markdown.
