
Slurm®-based Clusters
Deploy large-scale, customizable training environments with Nebius AI Slurm®* solution, featuring the NVIDIA stack, high-performance shared storage and advanced Slurm scheduling.
Ready-to-use cluster configuration
Quickly deploy a fully prepared cluster with preconfigured NVIDIA CUDA, NCCL, and InfiniBand drivers and libraries. With essential Slurm configurations in place, you can immediately start your high-scale training.
Best training experience
If a specific GPU or entire host has issues or underperforms, the Nebius-developed operator mitigates it by providing notifications or recreating the resource.
High-performance shared storage
Shared storage, powered by Nebius AI Shared Filesystem, delivers up to 30 GB/s performance for checkpoints and dataset processing.
Adjustable configuration
Easily adjust the number of nodes and type of GPUs, and scale your computational resources seamlessly at the start or anytime after deployment.
Easy environment management
Users and system packages are synchronized across nodes, simplifying maintenance tasks.
Advanced job scheduling
Utilize Slurm for sophisticated job scheduling to optimize resource usage, enhance throughput and minimize job turnaround time.
ML/AI cycle use cases where Slurm is essential
Data processing
Slurm has proven itself as an effective data processing tool, extensively used to create the state-of-the-art dataset Fineweb.
Slurm excels in handling batch processing jobs, such as dataset cleaning, transformation and augmentation, significantly reducing data preparation time for model training.

AI Model training
Slurm efficiently manages resources for training large-scale AI models, distributing tasks across multiple nodes to accelerate training times.
For models that require distributed training across multiple GPUs and nodes, Slurm coordinates the distribution, ensuring optimal resource utilization and synchronization.

High-performance computing (HPC)
Slurm enhances HPC systems by efficiently scheduling jobs and managing resources, ensuring optimal utilization and scalability from small clusters to large supercomputers.
Its customizable and fault-tolerant design, supported by a strong community, ensures reliable and adaptable performance in diverse HPC environments.
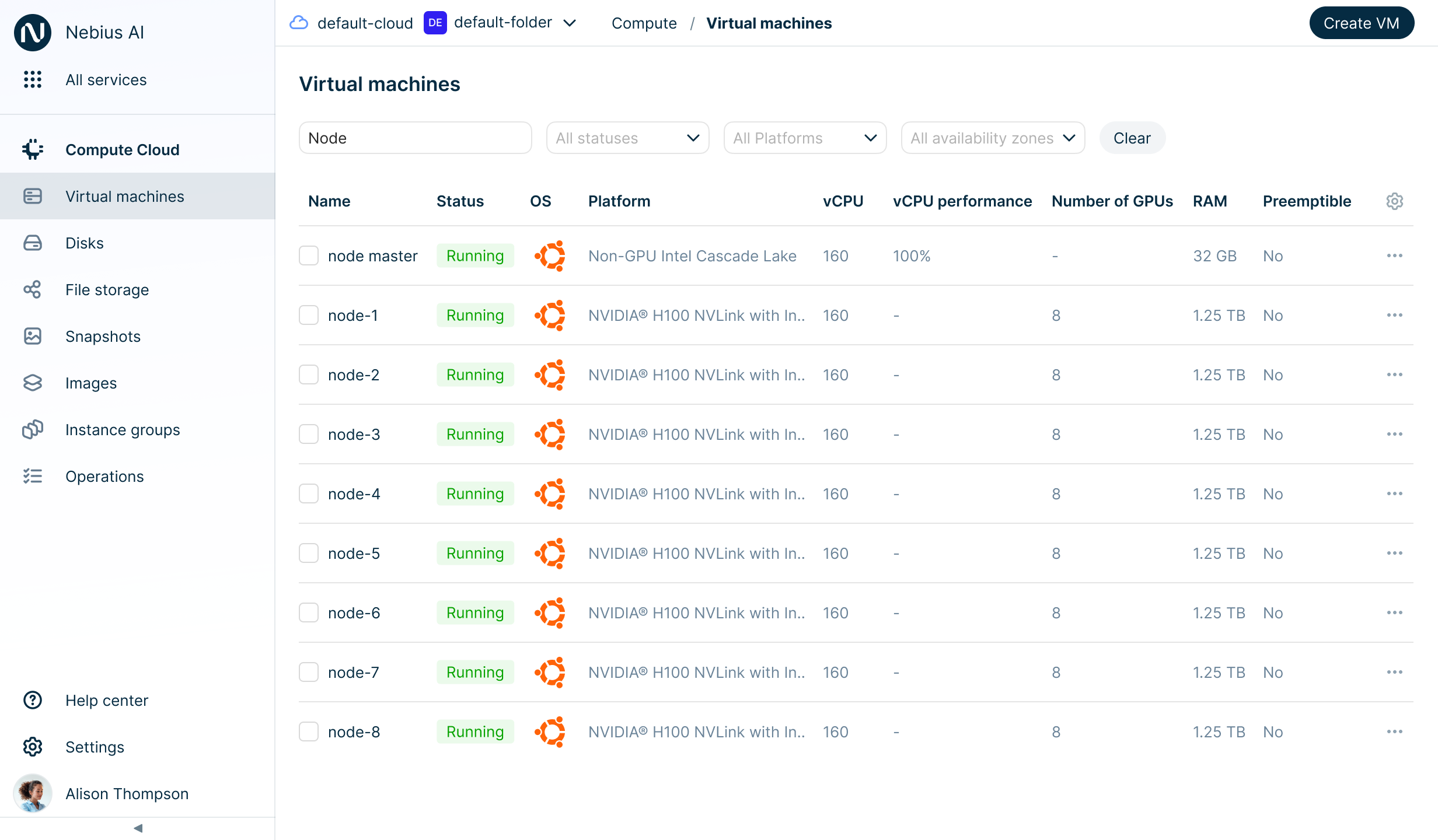
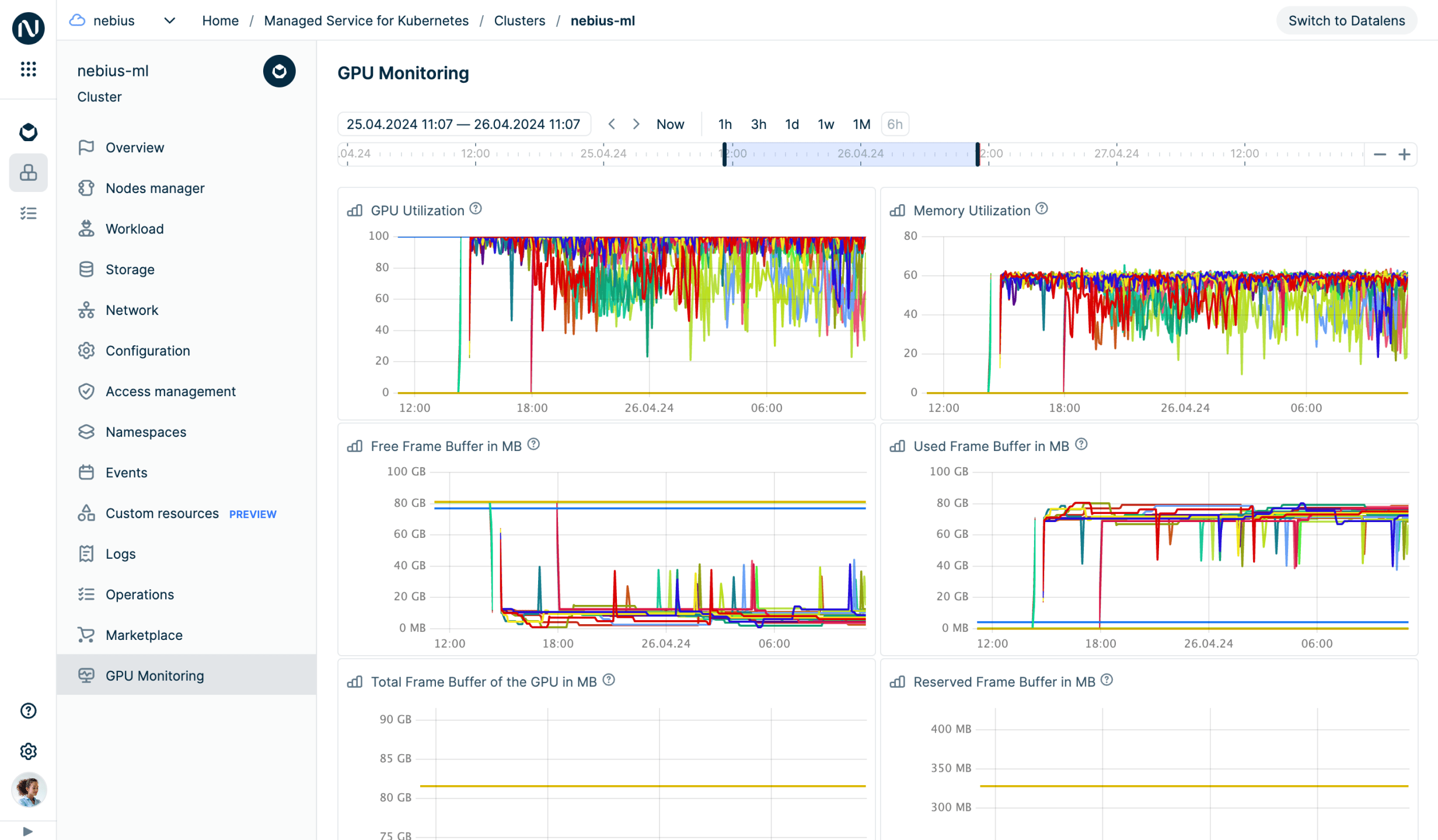
Intuitive cloud console for a smooth user experience
Intuitive cloud console for a smooth user experience
Create a VM with an operating system optimized for your tasks and monitor GPU usage.
Webinar recording: Scaling your machine learning workloads will eventually require resource orchestration. This webinar compares the most popular options today — Slurm and Kubernetes, covering their design origins, ML adaptations and other factors to consider.

Video tutorial: The team of Nebius AI cloud solution architects provides ML and MLOps engineers with a Terraform-based Slurm solution packaged with Pyxis and Enroot for container support. This video describes the solution on how to deploy a Slurm cluster of VMs with GPUs and InfiniBand networking.

Slurm-based Clusters: Q&A
What is Slurm?
What is Slurm?
Slurm is an open-source workload manager designed for high-performance computing (HPC) clusters.
When do I need Slurm?
When do I need Slurm?
Does Nebius AI solution provide InfiniBand support?
Does Nebius AI solution provide InfiniBand support?
How is Slurm different from Kubernetes?
How is Slurm different from Kubernetes?
SchedMD
SchedMD
By partnering directly with SchedMD, the developer of the Slurm Workload Manager, Nebius AI provides exceptional support to Slurm users. SchedMD robust Slum workload manager streamlines job scheduling and resource allocation. Its scalability and reliability make it a versatile solution that can meet a variety of business needs.
Start your journey
More to know
* — Slurm is a registered trademerk of SchedMD LLC.