
Demo: applying retrieval-augmented generation with open tools
Retrieval-augmented generation (RAG) is a technique that enhances language models by combining generative AI with a retrieval component. Let’s examine a quick example of applying RAG in a real-world context.
Large language models excel in various areas thanks to their training on extensive data across diverse topics, but they face challenges such as being resource-intensive and not always current. They lack real-time updates and access to private data, limiting their use in dynamic or confidential contexts. To address this, the RAG technique is being adopted to enhance LLMs for enterprise applications, enabling them to provide accurate, timely information by integrating up-to-date and proprietary data, especially crucial in regulated industries.
The RAG approach allows the model to dynamically retrieve and use relevant external knowledge or data at the time of prediction, improving its ability to provide accurate and contextually relevant responses. RAG is particularly useful for applications requiring up-to-date information or specific knowledge not contained within the model’s pre-existing training data.
Moving a little closer to our hands-on demo, let’s put ourselves in the context of a modern company with its numerous dashboards and metrics for a data-driven approach. Unfortunately, these dashboards often go underutilized, failing to deliver their intended value. The issue is surprisingly simple: users are frequently unaware of the dashboards' existence or the correct links to access them. Attempting to locate this information in chats or internal wikis proves challenging and is usually outdated.
Even when a dashboard is found, details on how metrics are calculated are often missing. In this scenario, a chatbot equipped with metadata about dashboards, including descriptions, owners, lists of metrics, and formulas, would be invaluable. However, given the sensitive nature of this information, it cannot be provided to LLM APIs for fine-tuning, nor is it feasible to retrain the model each time a new dashboard is created. Here, the RAG approach can offer significant benefits.
Summarizing the RAG architecture
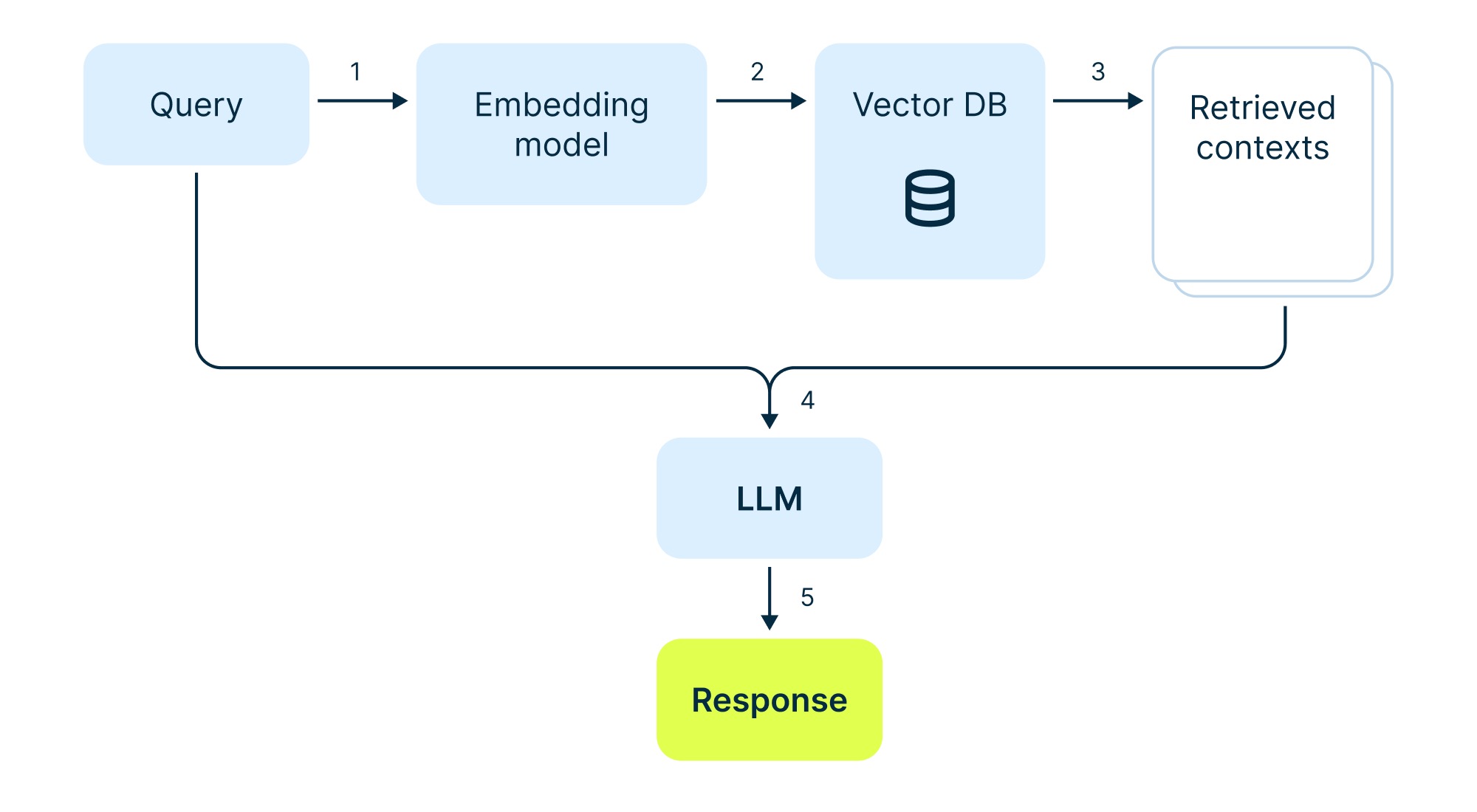
Step 1: Split the knowledge base into chunks
First of all, we would need the data itself. So, we need to create documentation for the dashboards. By the way, this could also be done with a multimodal LLM that can recognize an image of a dashboard. It creates quite good documentation as a draft to be reviewed by an analyst. Afterward, we can divide this data into chunks.
Step 2: Create embeddings and store in a database
Here, these chunks are turned into embeddings. Text embeddings, of course, involve converting text into numerical vectors that represent the text’s semantic meaning, enabling efficient searches and analyses within the database. This method is crucial in fields like natural language processing, supporting functionalities such as semantic search, clustering, and recommendation systems. These vectors are placed in vector databases optimized for storing and searching vectors.
Step 3: Retrieve query embeddings relevant to the user from the vector database
Now we’re ready to receive requests from business users. A user types something into the chatbot, and we send a search query to the vector database. It finds relevant text chunks and sends them to the LLM along with the user’s question. If these chunks are small and few, they are all sent to the model entirely. If there are many chunks, or we want to optimize model costs, we can sort them by relevance or shorten and prepare the chunks using a more affordable LLM agent.
Steps 4 and 5: Pass query and context to LLM and provide an answer to the user
After the LLM generates an answer, we present it to the user. We can utilize a single LLM or a series of agents if, for instance, one agent is more proficient with metric descriptions while another excels in dashboard descriptions, and so forth.
Let’s implement this described flow.
Creating the chatbot prototype
For higher reproducibility, we’ll use only open-source and free products, a stack that would be suitable for building a proof of concept. We’ll utilize:
-
Flowise, a low-code platform available to Nebius AI users via the Marketplace. Flowise features a user-friendly drag-and-drop interface, allowing the construction of applications by integrating APIs, local resources, and computing power to develop proof-of-concept chatbots. While crafting a custom production-ready solution through coding may prove to be more reliable, the platform is great for quick experiments like ours.
-
Pinecone, a vector database. It was selected as a cost-free solution for a proof of concept due to its convenient features for storing and searching embeddings. In our scenario, the distinctions among various vector databases are minimal, as we’re handling a small volume of data. However, the appeal of Pinecone lays in its ready-to-use API and cloud-based implementation, making it the preferred choice.
-
OpenAI API as the LLM and for creating embeddings. Its significance lies in its ease of use for PoC purposes, supported by Flowise through prebuilt blocks and connections. However, it’s important to note that while this setup is convenient for initial stages, deploying our chatbot at scale using the OpenAI API could become a costly option.
You can, of course, apply different tools if you have more experience dealing with them — our prototype implies using the common functionality of each tool, so all of them are more or less replaceable.
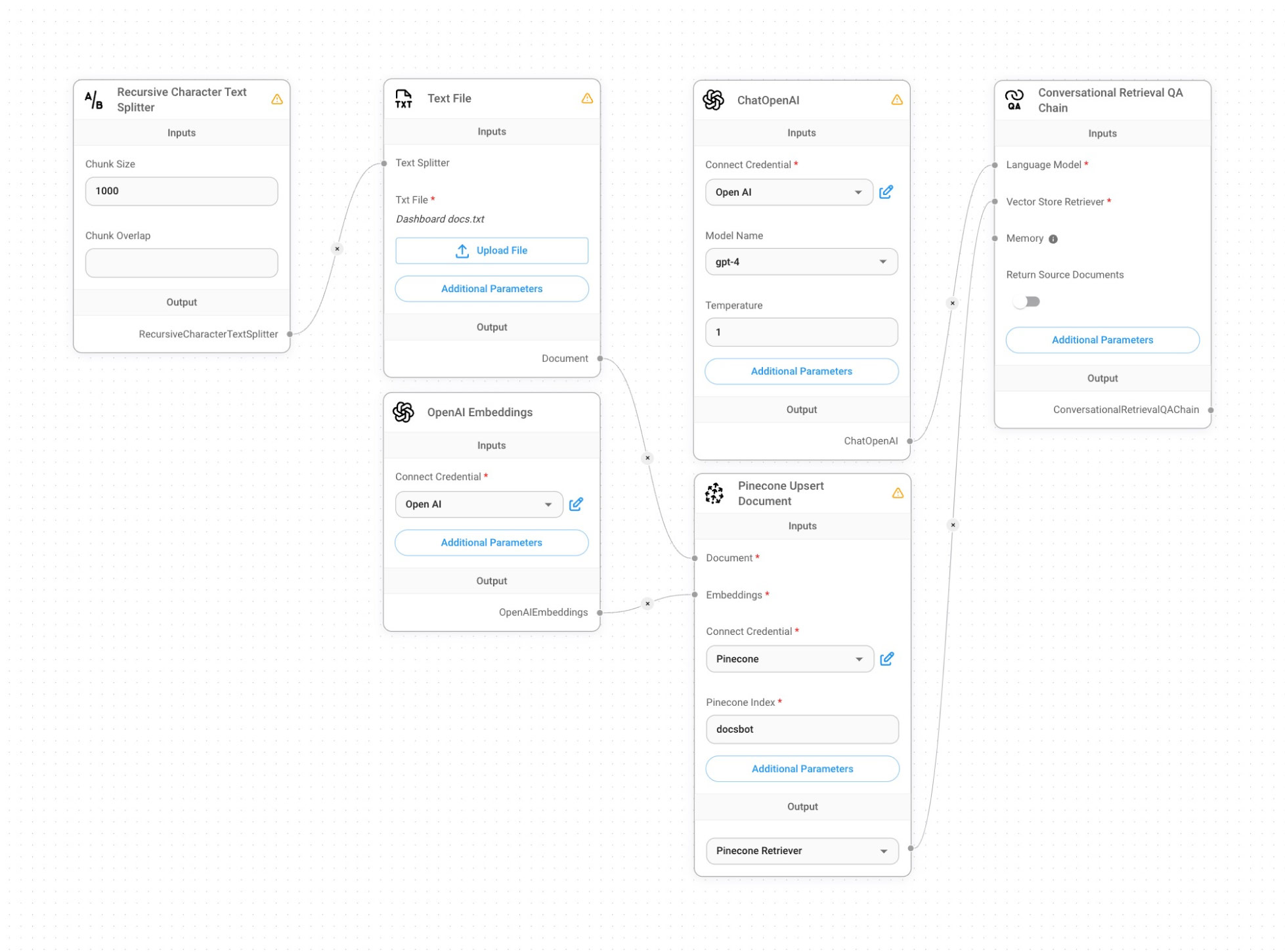
Here are the blocks we’ve created in Flowise:
Text File — We upload our knowledge base to a storage, representing step 1 from our initial scheme above.
Recursive Charter Text Splitter — Splitting the knowledge base into chunks, still representing step 1 from our scheme above.
OpenAI Embeddings — Here, we create embeddings (vectors) from text chunks, therefore moving to step 2 from our scheme.
Pinecone Upsert Document — We take each vector and store it in the vector database (step 3).
Conversational Retrieval QA Chain allows us to orchestrate the process of retrieval-augmented generation (step 4). We get the user requests, make a search in the vector database, and send selected vectors to the LLM.
ChatOpenAI — We define the model as well as its parameters, and, through the API, call ChatGPT, which we use as LLM (still step 4).
And that’s it, the prototype is ready. Here’s how a conversation with our just-built chatbot might look like:
Feel free to reproduce the prototype, make your own adjustments, and/or add some blocks, further intensifying the complexity of the scheme. Consider how your case can relate to this pipeline. One of the possible ways to start is by deploying Flowise on Nebius AI. I hope that this quick demo helped you in understanding some of the basics surrounding RAG and that you can now have some fun building something equally advanced from simple blocks in the visual low-code UI.
Next up: the webinar on building a production-ready RAG solution
By following in our footsteps from this article, you can create what is precisely a proof of concept. It has the necessary proof-of-concept qualities such as clarity, simplicity, and really fast deployment, but managing data this way as a production solution would be expensive at scale and wouldn’t be efficient or reliable. So the natural next step is to build a production environment for applying RAG — the topic of our upcoming webinar, which will take place on May 16. You can learn more and register for the webinar here.
Explore Nebius AI
