
Nebius AI monthly digest, February 2024
In the last few weeks, we held our first webinar featuring Recraft, updated docs with some useful guides, shared Dubformer’s AI dubbing story, tackled the topic of AI research, and have been expanding our portfolio of ML-related products on Marketplace.
Videos
20B foundational model: what it takes to train it
Nebius AI and Recraft shared the experience of training the 20B parameters foundational model. Recraft started using our platform at the technical preview stage. As one of the early adopters, they contributed to creating the new AI cloud. You will learn about all the challenges and how both teams worked together to overcome them.
Configuring network in Nebius AI
Meet Khamzet Shogenov, our cloud solutions architect, discussing networking basics within Nebius AI platform. This includes creating and managing networks, configuring remote and internet access, setting up custom routing rules, and more.
Docs and blog
Deploying a K8s cluster
In the previous digest, we shared new articles in our documentation on utilizing GPUs and InfiniBand-powered GPU clusters with VMs. Now it’s Kubernetes' turn. The new guide will walk you through deploying a cluster in Managed Kubernetes, adding InfiniBand-connected GPUs to it, and testing the connection. Additionally, there are updates to relevant routine guides, such as the instructions for creating node groups.
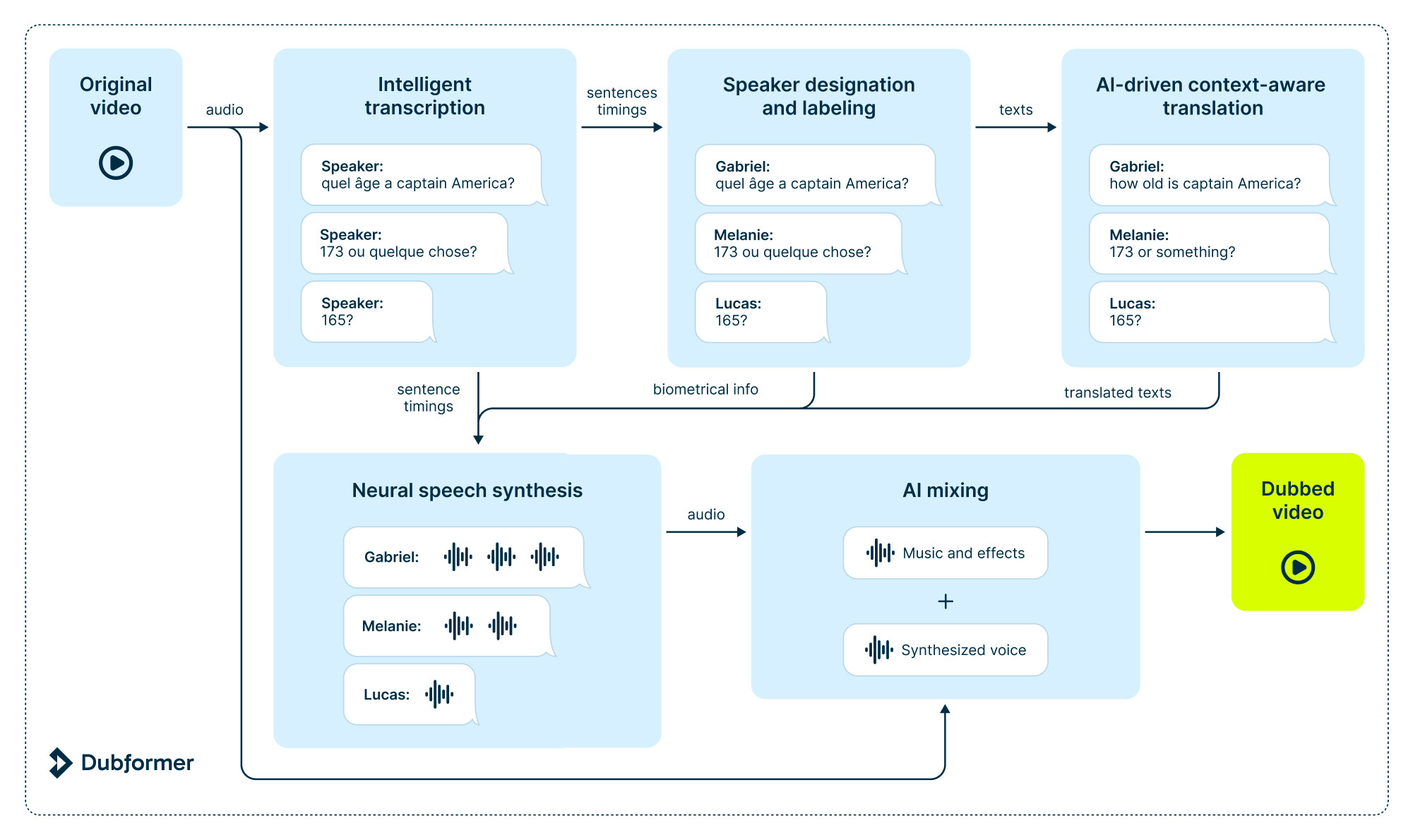
How Dubformer performs AI dubbing on Nebius infrastructure
Dubformer is a secure AI dubbing and end-to-end localization solution that guarantees broadcast quality in over 70 languages. The company manages two of its most resource-intensive tasks on Nebius AI: ML itself and the deployment of models.
Joining AI research community
ML communities in industry and academia differ greatly. We’re bringing them a bit closer with an overview of the research world for ML practitioners. Take a moment to explore the neighboring domain, which is much more accessible than it seems.
Marketplace product releases

Kubernetes Operator for Apache Spark™
Spark unifies the processing of your data in batches and real-time streaming, using your preferred language: Python, SQL, Scala, Java, or R. The open-sourced operator handles Spark applications the same way as other K8s workloads.

Kubernetes Operator for Apache Flink®
Flink is a stream processing framework for building robust, scalable, and high-performance applications. To manage them and their lifecycle using native K8s tooling like kubectl, use the Flink K8s Operator.

Flowise
Flowise is a platform designed for seamless innovation with a low-code approach and convenient UI. It brings about the transition from testing to production through fast and easy iterations.

Milvus
Cloud-native, open-source vector database that allows you to store, index, and manage massive embedding vectors generated by deep neural networks and other models. You can deploy Milvus on your clusters using this product.

NVIDIA GPU Operator
It helps you provision GPUs in Kubernetes clusters. By using the operator pattern to extend Kubernetes, NVIDIA GPU Operator automatically manages the components needed to provision graphic cards.

NVIDIA Network Operator
K8s application designed for managing and optimizing software components for networking between NVIDIA GPUs in the cloud. The operator automates many tasks related to network setup.

Trino
Query engine tailored for efficient, low-latency analytics. Deploy it to seamlessly query your exabyte-scale data lakes and vast data warehouses. This ANSI SQL-compliant engine collaborates with BI tools like R, Tableau, Power BI, Superset, and more. You can access data from multiple systems within a single query, enabling insightful correlations.

Grafana Loki
Horizontally scalable, highly available, multi-tenant log aggregation system. It supports a wide range of log formats, sources, and clients, and allows formatting logs at query time rather than at ingestion. Integrations with Prometheus, Grafana, and Kubernetes are supported natively, providing a one-stop-shop UI for metrics, logs, and traces.

Horovod
Open-source distributed training framework optimized for cloud-based machine learning workloads. The primary motivation for Horovod is to make it easy to take a single-GPU training script and scale it to train across many GPUs in parallel. With Horovod, you can use the same infrastructure to train models with any framework, making it easy to switch between TensorFlow, PyTorch, MXNet, and other frameworks.

Apache Superset™
Flexible data exploration and data visualization platform with intuitive interface, capable to replace or augment proprietary business intelligence tools. Designed to cater to the specific needs of software development projects, Superset empowers users to create context-rich visualizations through charts and other visualization methods. Superset can be integrated with a different databases like MySQL, PostgreSQL, and more.

Stable Diffusion web UI
Browser interface for one of the most popular text-to-image deep learning models. Powered by Gradio, the UI features basic and advanced Stable Diffusion capabilities, such as original txt2img and img2img modes, outpainting, inpainting and upscaling, weighted prompts and prompt matrices, loopback, and many more.

Qdrant
API that provides the OpenAPI v3 specification, allowing the generation of client libraries in various programming languages. The system implements a customised version of the Hierarchical Navigable Small World (HNSW) algorithm for Approximate Nearest Neighbor Search, ensuring fast and accurate searches.
Get in touch if you need GPUs
ML pipeline stages
