
Fundamentals of LoRA and low‑rank fine-tuning
In the next installment of our series of deep technical articles on AI research, let’s switch our attention to the famous LoRA, a low-rank adaptation technique.
1. Introduction
It’s easy to understand why we resort to parameter-efficient fine-tuning of LLMs: fully training them is an extremely costly process.
However, it turns out that a strong pre-trained model doesn’t require many parameters to be adapted for a specific task! This was known as early as 2020 when the authors of Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning ran several experiments with encoder-only models of the BERT and RoBERTa classes to explore the 'intrinsic dimensions' of various problems.
Specifically, they analyzed several tasks, and for each, they determined : the minimum dimension for which fine-tuning in a -dimensional subspace gives more than 90 percent of full fine-tuning quality. Like this:
![]()
The dashed line represents the value, and you can see that in many cases, it can be achieved with a significantly smaller than . Note, by the way, that the horizontal axis is logarithmic.
As LLMs matured, several low-parameter fine-tuning techniques emerged, and the most influential of them is LoRA — the abbreviation comes from low-rank adaptation.
In this long read, we will discuss LoRA and some of its modifications. Namely, I will share with you:
- What is rank from a math point of view, and how to wrap your intuition around it.
- What exactly we mean by fine-tuning a model in a low-dimensional subspace.
- Why LoRA updates come in a two-matrix-product form.
- Which exciting developments arose around LoRA recently.
2. A few words about rank
There are many kinds of layers inside LLMs, but in the end their parameters are stored in matrices (luckily, you don’t often encounter tensors in LLMs). And each matrix has a characteristic called rank. Usually, rank is defined like this:
The rank of a matrix is the maximum number of linearly independent columns (or rows) that can be found in the matrix. (You’ll get the same number if you take rows instead of columns).
While this definition is correct, my experience shows it’s not easy to use. So, let’s consider an equivalent one.
A real matrix of size is usually more than just a table filled with numbers; it can represent a variety of algebraic entities. Importantly for our discussion, it can represent a linear transformation mapping from an -dimensional space to an -dimensional space (mind the order!). My favorite way to characterize rank is:
The rank of a matrix is , the dimension of the image of .
For example, if is , it represents a linear transformation , and its rank could be (top picture), or (bottom picture), or even if the image is zero:
![]()
While I won’t formally prove the equivalence of these two definitions here, let me remind you that the columns of a matrix of a linear transformation are precisely the images of the standard basis vectors. Here is an example of a matrix corresponding to a linear map :

If you need a basis for the image of , you can take a maximal linearly independent subset of , such as . Thus, the rank is .
3. Low-rank adaptation — LoRA
The essence of LoRA is:
Let’s only do low-rank parameter updates.
To clarify, consider some weight matrix , which is, of course, a matrix of some linear transformation . A low-dimensional update of is a new transformation :
where the image of is low-dimensional.
Here is an example where and has a rank of :
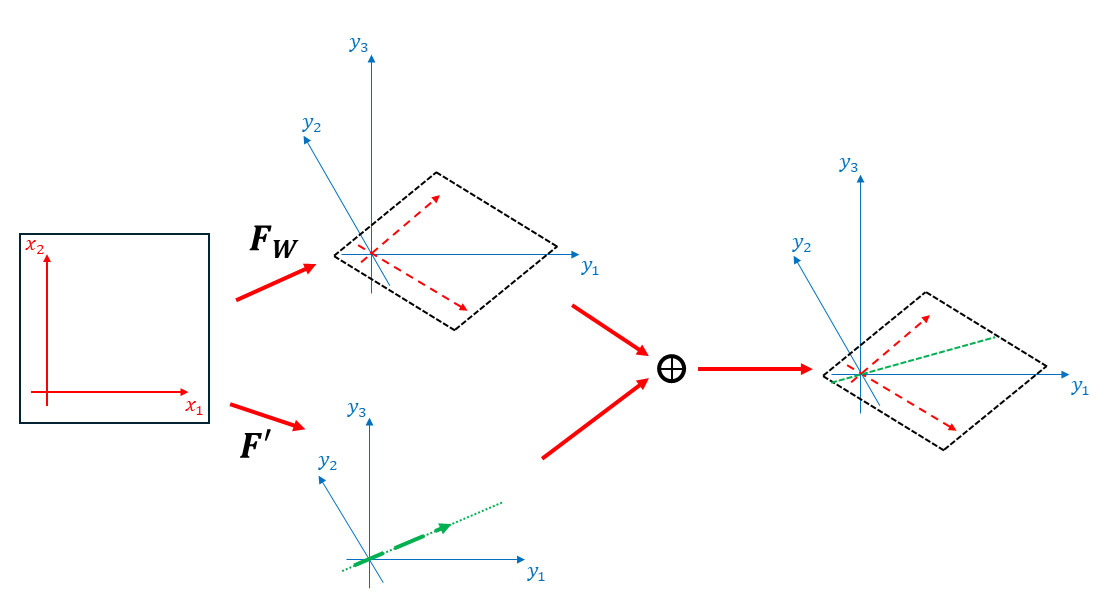
You see that adding changes only what happens on the green line.
LoRA suggests the following:
- We freeze ,
- We only fine tune , and we demand that the rank of its matrix is , where is a hyperparameter.
The problem is that optimizing over a subset is usually tricky, to say the least. Can we find a convenient parametrization for rank- matrices? It turns out that yes, and for this purpose, we will revisit our dimension-of-the-image description of rank.
4. Parametrizing a low-rank matrix
Let’s take another look at our rank-1 example:
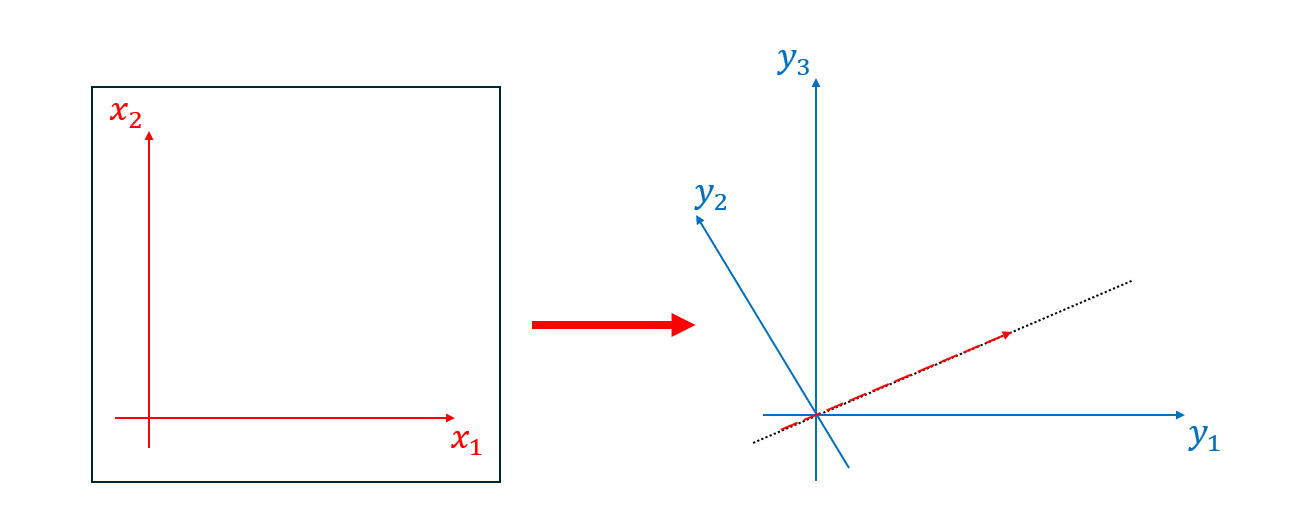
This transformation can be done in two stages:
- First, we map a 2d plane onto a line using a matrix of shape .
- Then, we embed this line into a 3d space using a matrix of shape .
Like this:
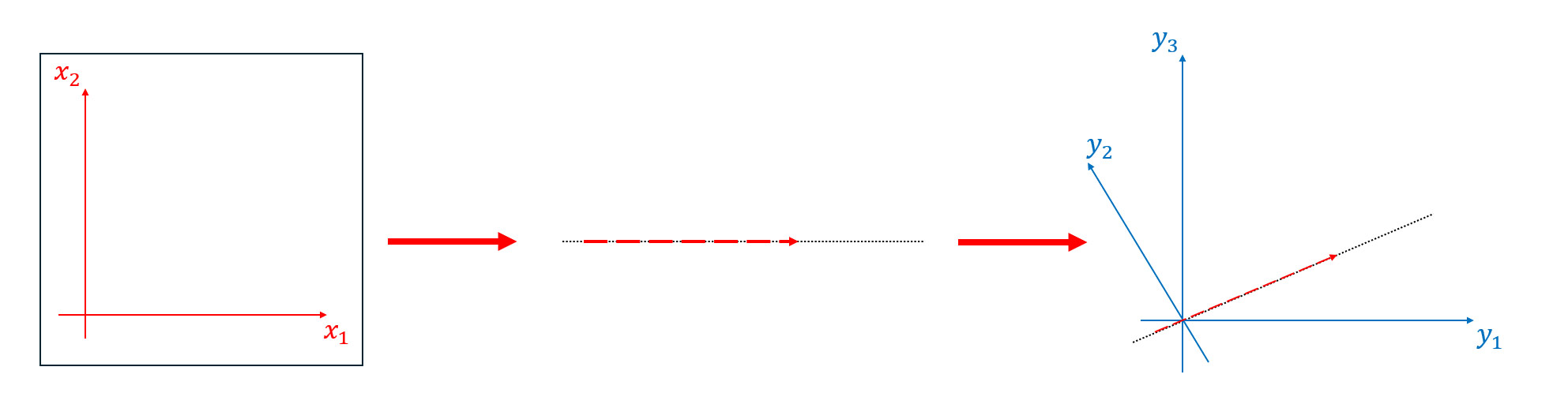
Now, we have or, in matrix terms:
In exactly the same way, we can demonstrate that any matrix of rank can be decomposed as
Moreover, if there is a decomposition
then . Note: the rank can be less if the ranks of and are less than .
And that’s exactly what we do in LoRA. We decompose and train matrices and without any additional constraints!
Now, you should better understand what happens in this image (sourced from here):
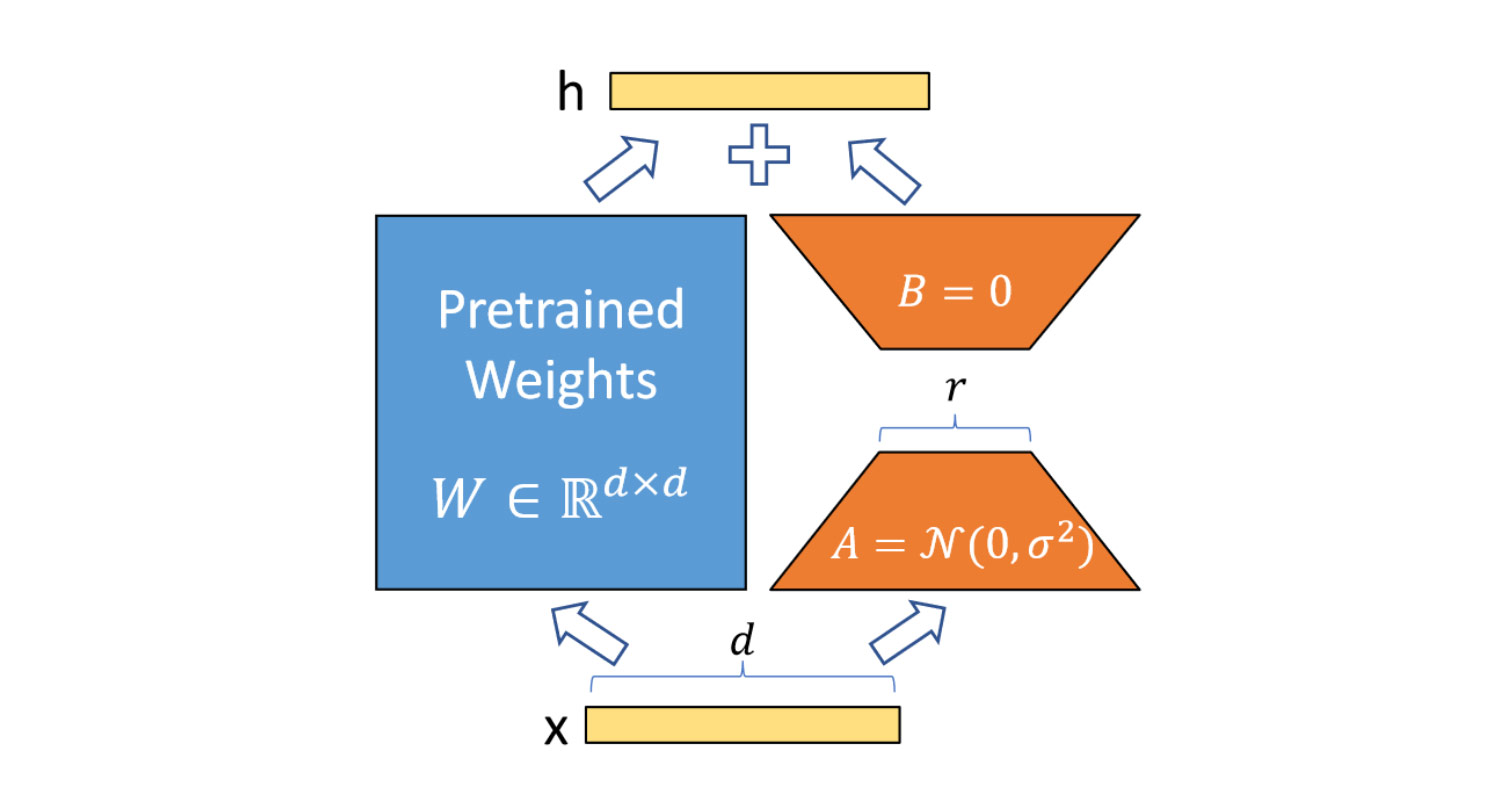
Now, we can explicitly calculate how much additional memory LoRA requires. For example, if the original was , like in Mistral’s q_proj layer, and the LoRA rank is , then
- is of shape ,
- is of shape ,
giving new parameters which is only about of the parameters of .
There is no general rule, but usually quite small values of are used. It’s reasonable to go with , or , or, if you’re especially generous, with , although I wouldn’t start with it. Usually, all dense layers, except for the embedding layer, are fine-tuned, that is:
- Query, key and value projections (q_proj, k_proj, v_proj layers) and the output projection of the attention block (o_proj layers),
- All the dense layers inside the Feedforward block.
Often, a dropout layer is also added before with or likewise small.
The one thing I would add is how we initialize and . We want to start fine-tuning from the pre-trained weights , so should initially be zero. It’s easy to do this by setting the initial to zero, as depicted in the image above.
LoRA has proven itself a worthy companion for any LLM engineer and a default choice for fine-tuning tasks.
It has been observed, though, that LoRA often yields worse results than full fine-tuning. Of course, we could blame a lack of parameters, but there are additional inefficiencies in LoRA, which we’ll discuss in upcoming sections.
4.1. Intrinsic dimensionality: experiment details
I previously mentioned the paper Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, which showcased that certain task can be successfully solved with low dimensional parameter updates. I skipped the details of the experiment setup, so I’ll briefly explain it now.
The LoRA update is expressed as:
where projects to an -dimensional (low-dimensional) space, and embeds the latter into the image space of .
What the authors of the Intrinsic Dimensionality paper did is:
- They took specially structured random and froze it.
- They then trained .
This means that for each experiment, they fixed a random subspace and trained the updates within it, while LoRA trains both the subspace () and the updates within it ().
It’s interesting that we can get meaningful results even when making updates in a randomly selected subspace with a random frozen . But of course, it’s much better to make them trainable.
5. PiSSA: using SVD to do updates in a more meaningful subspace
When we’re implemetingwe implementdo LoRA, evolves through stochastic gradient descent, allowing the subspace where the updates occur and, develop randomly. This raises the question: can we identify a 'good' starting subspace?
The answer might be yes. We have a good old method for identifying 'meaningful' subspaces, known as singular value decomposition (SVD). Let’s briefly revisit what it is.
By definition, a singular value decomposition (SVD) of a matrix is
where:
-
is orthogonal, meaning the columns of are mutually orthogonal vectors of length : for , and . (The same is true for rows of because is square).
-
is also orthogonal.
-
is diagonal with . These are known as the singular values of . Just be aware that is not always square; for example:
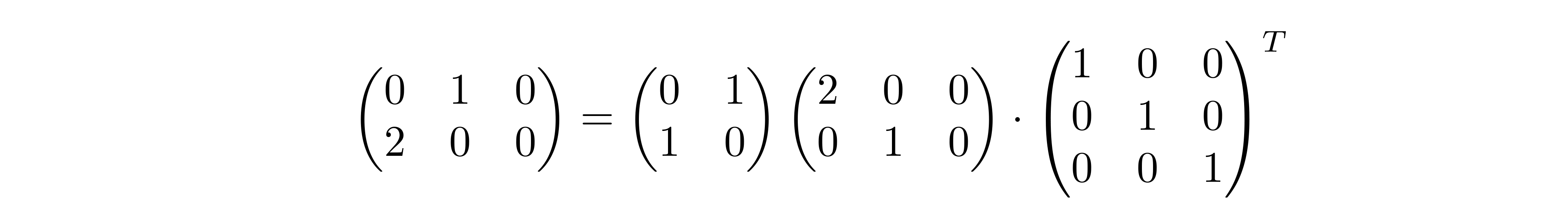
To move on, we need to tinker with matrices a bit. First, we can put into the columns of and the rows of (which are the transposed columns of ):
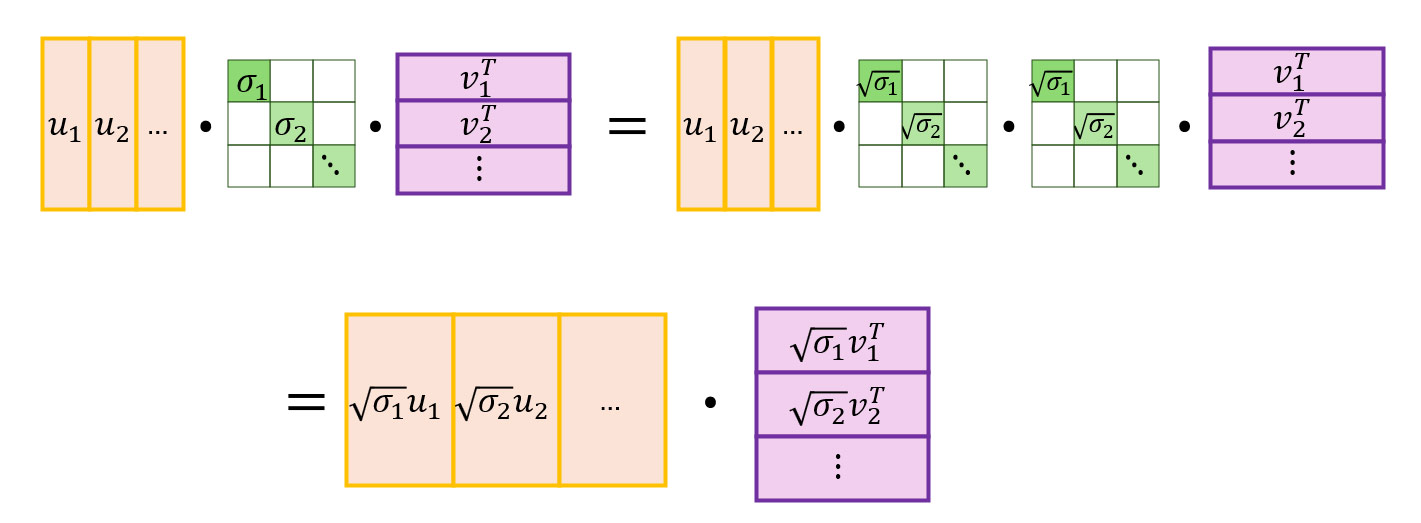
Next, we use the following matrix identity:
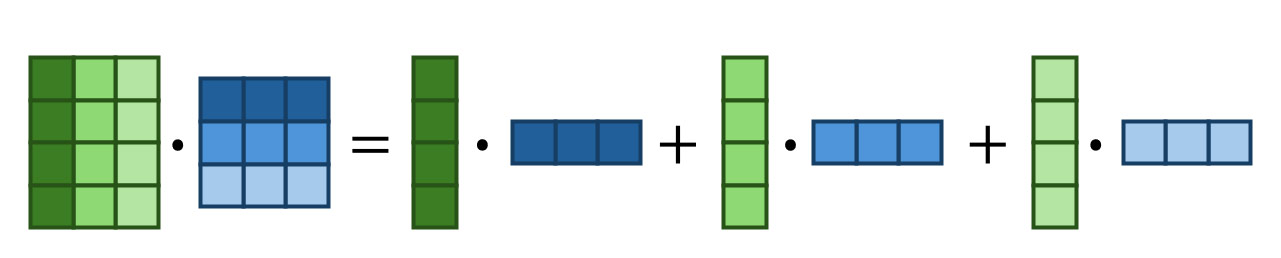
to reformulate SVD as:
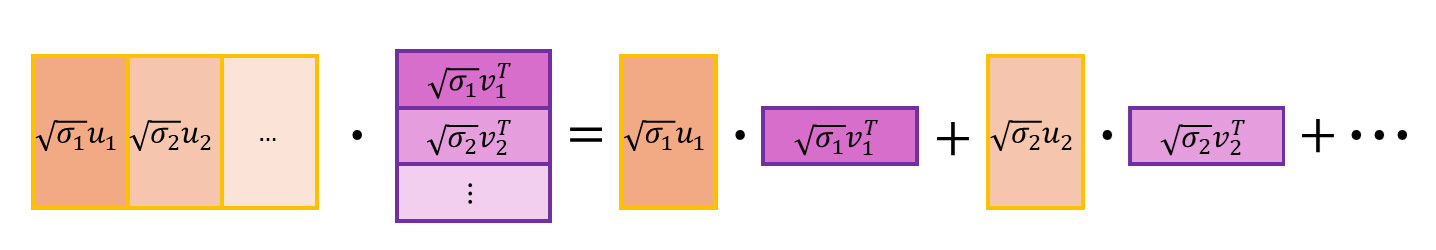
Now, let’s recall that . Moreover, in most real cases, the singular values decline rapidly, enabling us to select a reasonable such that is significantly less than . We can then suggest that
- encapsulates the meaningful components, while
- represents 'noise'.
Reapplying the green-and-blue matrix identity, we can depict it this way:

Here, the first part of the sum is meaningful and the second is 'noise'. We can distill this further into:
Here’s what we have here:
- The summand likely represents the 'important' part of the matrix.
- is a projection to an -dimensional space, while embeds this space into the image space of as the -dimensional subspace .
Caution! When using SVD, we persuade ourselves that all the interesting things happen in . However, this is not always true. The principal components are larger but not necessarily more interesting or useful. Sometimes, the finest details are the most important ones. However, SVD may give us a good starting point for training LoRA.
The PiSSA paper suggests exactly that. The authors take
as we did earlier and further fine-tune and . The results are nice; the authors claim to beat LoRA in their experiments, and they also show that PiSSA performs better than QLoRA in a quantization strategy when the base model is set to 'nf4' precision and frozen, while the adapters are trained using 'bfloat16' precision.
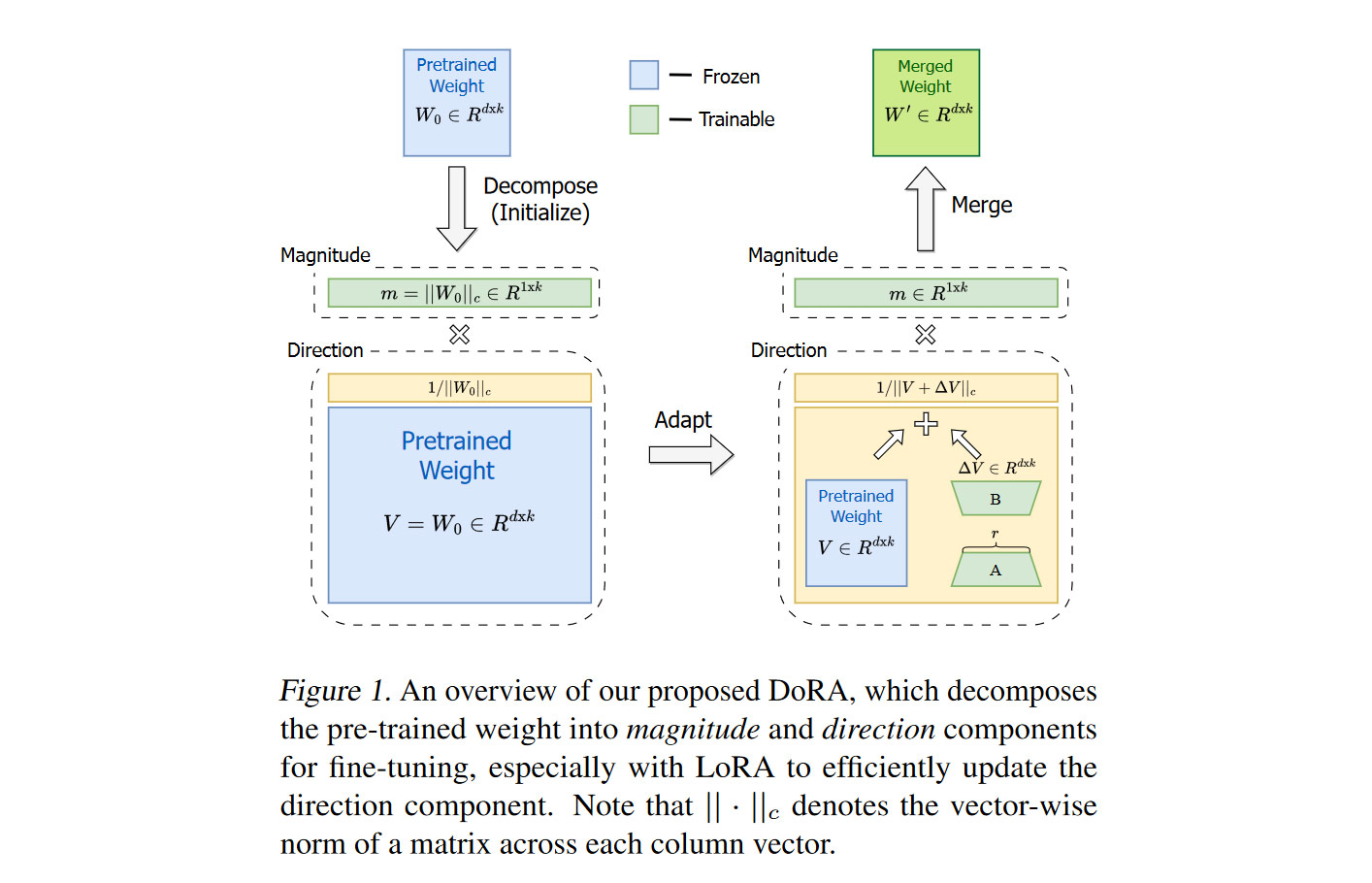
6. DoRA: decoupling magnitude and direction updates
The authors of DoRA: Weight-Decomposed Low-Rank Adaptation did an insightful analysis of magnitude and direction updates during full fine-tuning versus LoRA.
Consider the columns of the weight matrix
As we remember, each is the image under of the standard basis vector . During fine-tuning, the vectors change in both magnitude and direction. It’s curious to see that the patterns of these changes differ between full fine-tuning (FT) and LoRA. Let’s explore how. We decompose the matrix as
where , also denoted by (magnitudes), is the vector
(directions) is the following matrix:
and stands for a special kind of element-wise product.
Now, here’s an image illustrating the patterns of change:
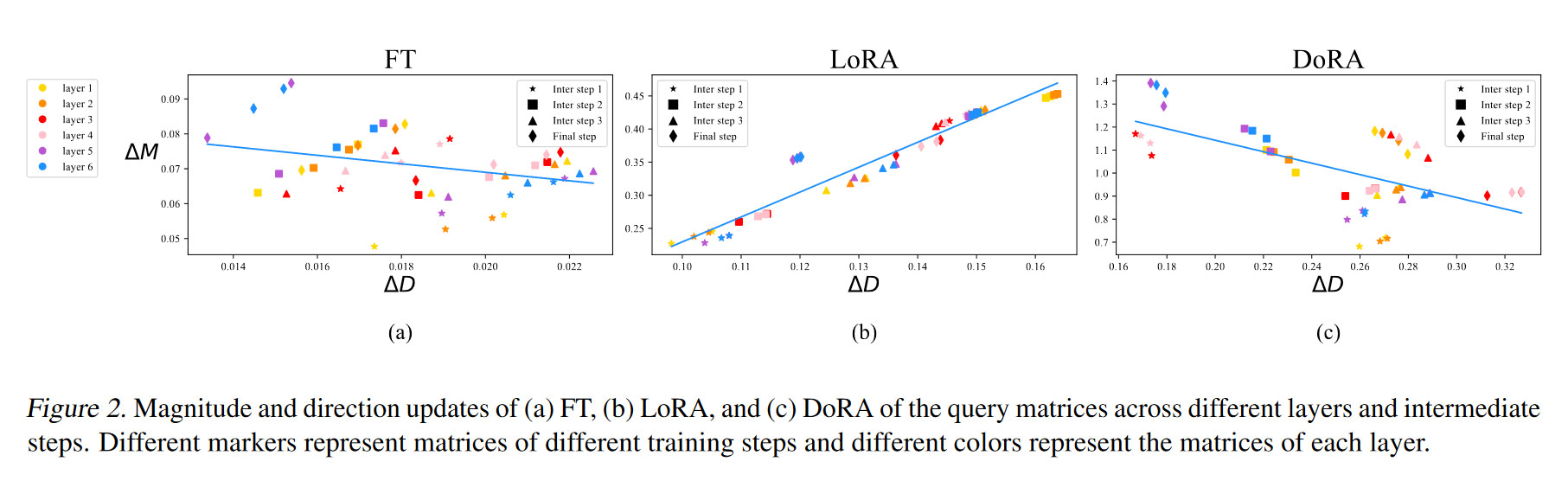
On the axis, we have MAE between before and after fine-tuning. On the axis, we have mean distance between before and after fine-tuning.
For LoRA, there is a notable positive correlation between and , while for full fine-tuning (FT), these values exhibit a weaker negative correlation. This hints that in LoRA, magnitudes and directions might become entangled in a suboptimal way. To address this, the authors of DORA suggest decoupling them during fine-tuning. Specifically, they update the weight matrix as
where:
- is the initial before fine-tuning,
- is a trainable magnitude vector, initialized as ,
- is a low-rank LoRA summand with trainable matrices and ,
- Division by means division of each column of by its length.
The method can be summarized in this table:
As you could see in the earlier plots, the correlation between magnitude and direction updates exhibits a weak negative correlation, similar to what we see in full fine-tuning. This correlation can be really important, as in experiments, DORA consistently outperformed LoRA (well, if +1 point in quality is enough for you).
This article was inspired by my experience of teaching linear algebra and by discussions at the paperwatch meetings of the Practical Generative AI course by School of AI and Data Technologies. If you’re interested in studying LLMs and other generative models, their internal workings and applications, check out our program.
Explore Nebius AI
