
H100 and other GPUs — which are relevant for your ML workload?
Let’s break down the differences between NVIDIA’s top-tier GPUs and identify workloads where each GPU model performs at its best.
My name is Igor, I’m the Technical Product Manager for IaaS at Nebius AI. Today, I’m going to explore some of the most popular chips: NVIDIA Tensor Core H100, L4, and L40; A100 from the previous gen; and V100, occasionally used by some cloud providers. This way we will cover a powerhouse Hopper, Ada Lovelace, Ampere, and Volta microarchitectures. As for the newly announced H200, NVIDIA positions it as a next step based on the H100 with a slightly different RAM, and we have yet to explore the finer details. Stay tuned for updates.
Before examining the differences between the chips, it’s important to highlight some relevant properties of the transformer neural networks and numerical precisions. This will give us a new perspective in terms of how graphics cards evolved and what are the intended use cases for them.
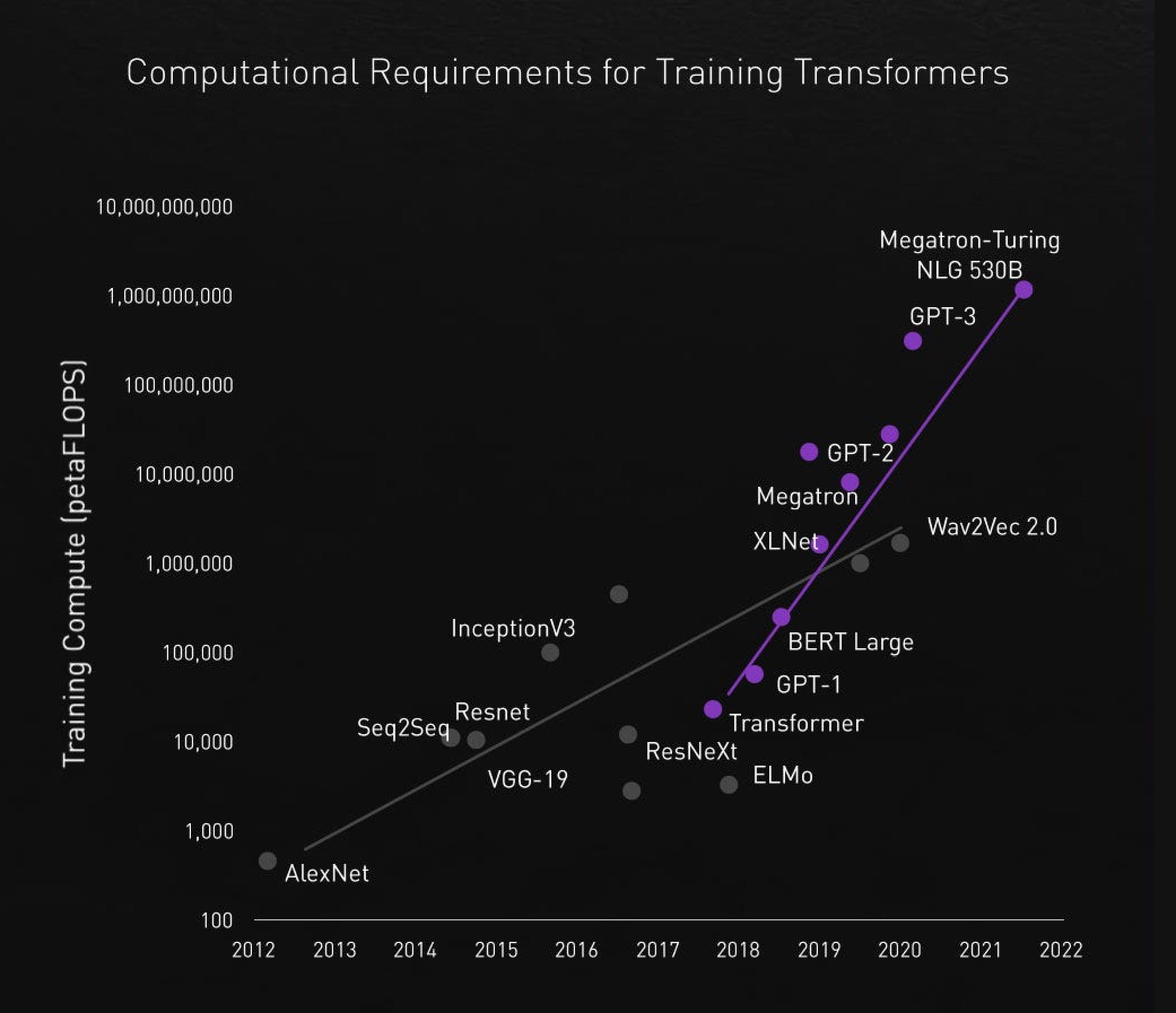
The reason we should specifically discuss transformers is that the latest GPUs were designed first and foremost with this architecture in mind. It is one of today’s most notable neural network types. Transformers are believed to have originated at Google in 2017 with the publication of their paper, 'Attention is all you need.' This study introduced the self-attention algorithm, the cornerstone of transformer architecture. Almost immediately, the popularity of this model skyrocketed. Today, transformer-based models have largely eclipsed other varieties, such as recurrent and convolutional neural networks. In fact, transformers are the default choice for a wide range of tasks in nearly every domain. For a more illustrative perspective, consider this part of a lecture given by Andrej Karpathy at Stanford.
Why are transformer models trending?
1. Transformers consistently outperform their counterparts when pre-trained on large, unlabeled datasets and then fine-tuned on smaller, high-quality labeled datasets. While this training method is not new, transformers excel at it. Their effectiveness is twofold: during pre-training (benefiting from data volume) and during fine-tuning (benefiting from data quality). The more data we have in the pre-training phase and the higher the quality of the data during fine-tuning, the better the model’s accuracy.
In other neural network architectures, achieving comparable quality would demand a top-notch dataset from the start, requiring data scientists to refine vast swaths of data — a task both costly and time-consuming. Transformers, however, bypass pre-training data labeling by humans. Overcoming this bottleneck enables training on much larger datasets than before.
In addition, a fundamental distinction of the transformer from its predecessors is that you can train it on mostly unrefined data for broad applications. After that, you can fine-tune the model for narrower scenarios. Older models, by contrast, typically require more thorough data preparation and preprocessing.
Take popular models like Falcon and Llama as examples. They initially underwent broad-spectrum training and can be fine-tuned for specific scenarios using labeled data.
2. Transformers are characterized by highly parallelizable computations. With no loops or sequential operations, transformer models can be easily distributed across multiple machines.
They also mesh well with Tensor cores, powering NVIDIA’s latest GPUs such as H100, largely because their underlying algorithms revolve around matrix multiplication — a task for which Tensor cores were built. But there’s a caveat: while you can technically write any code — even code that doesn’t use Tensor cores at all — a model like that is doomed to be inefficient. Transformers, on the other hand, utilize such cores with the highest efficiency.
3. Stemming from the previous two points, there’s still tons of untapped potential to scale and improve models by expanding datasets and increasing computational power. This is the most straightforward and intuitive approach. Here’s the podcast, where Dario Amodei, the CEO of Anthropic, one of the leading AI research ventures, is discussing such ideas.
While some express concerns that this trend may slow down as we run out of usable data, others are looking into synthetic data generation. For instance, some ML teams use intricate prompts to extract data on specific topics from established LLMs like ChatGPT. This data is then fed into other models to improve their performance.
4. As transformer architecture has become the industry standard, frameworks and GPU hardware are tailored to favor transformers, adding to the momentum of the “transformers for everything” wave.
The role of numerical precision
The massive success of NVIDIA’s latest GPU lineup — H100, L4, and L40 — wouldn’t be possible without hardware support for FP8-precision support, especially significant for transformer models. But what is it that makes FP8 support so important? Let’s dive in.
FP, short for “floating point, ” refers to various numerical representation formats. In the context of our article, it’s about the precision of the numbers a model stores in RAM and uses in its operations. Most importantly, these numbers determine the quality of the model’s output. Here are some key numerical formats to give you a better picture:
FP64, or the double-precision floating-point format, is a format in which each number occupies 64 bits of memory. While this format isn’t used in ML, it has a place in the scientific domain. The L40 and L4 GPUs do not support FP64 precision at the hardware level, a point we’ll get to later. Therefore, they’re not suitable for scientific applications.
FP32 and FP16: For a long time, FP32 was the de facto standard for all deep learning computations. However, data scientists later discovered that converting model parameters to the FP16 format resulted in reduced memory consumption and faster computation, seemingly without compromising quality. As a result, FP16 became the new gold standard.
TF32: Another format crucial to our discussion. Before entering the computation in processing FP32 values on Tensor cores, such values can be converted to the TF32 format at the driver level automatically — no changes in code needed. Without going into too much detail, TF32, while slightly different, offers faster computation. That said, it’s possible to code in such a way that the model interprets FP32 on Tensor cores.
INT8: This is an integer format and doesn’t involve floats. After training, model parameters can be converted to another type that uses less memory, such as INT8. This technique, known as post-training quantization, reduces memory requirements and speeds up inference. It has worked wonders for many model architectures — but transformers are an exception.
Transformers can’t be converted post-training to reduce hardware requirements for inference. Innovative techniques like quantization-aware training do offer a workaround during training, but re-training existing models can be expensive and very challenging.
FP8: This format addresses the above issues, most notably for transformer models. With FP8, it is possible to take a pre-trained transformer model, convert its parameters to the FP8 format, and then switch from an A100 to an H100. You can do that without converting as well and still gain performance just because H100 is simply faster. However, thanks to FP8, you’ll only need about a quarter of the graphics cards to infer the same model with identical performance and load. Mixed-precision training using FP8 is also a good idea — the process would wrap up quicker, would require less RAM, and later during the inference stage, converting would no longer be necessary, as the model’s parameters would already be the FP8 ones where possible.
What types of GPU cores exist
Now it’s time to briefly discuss the differences between the types of GPU cores, which will be crucial to our conclusions.
-
CUDA cores: These are general-purpose cores that can be adapted to a variety of tasks. While they can handle any computation, they aren’t as efficient as specialized cores.
-
Tensor cores: Designed for matrix multiplication, these cores excel at this particular task. This specialization makes them the standard choice for deep learning.
-
RT (ray tracing) cores: These cores are optimized for tasks that involve ray tracing, such as rendering images or video. When the goal is to produce photorealistic imagery, a GPU outfitted with RT cores is the way to go.
Almost every GPU model relevant to this article comes equipped with both CUDA and Tensor cores. However, only the L4 and L40 have RT cores.
Key GPU specs and performance benchmarks for ML, HPC, and graphics
With the numerical formats out of the way, let’s turn our attention to the evolution of GPU specs and their standout features. We’ll focus only on the technical specifications relevant to the context of this article.
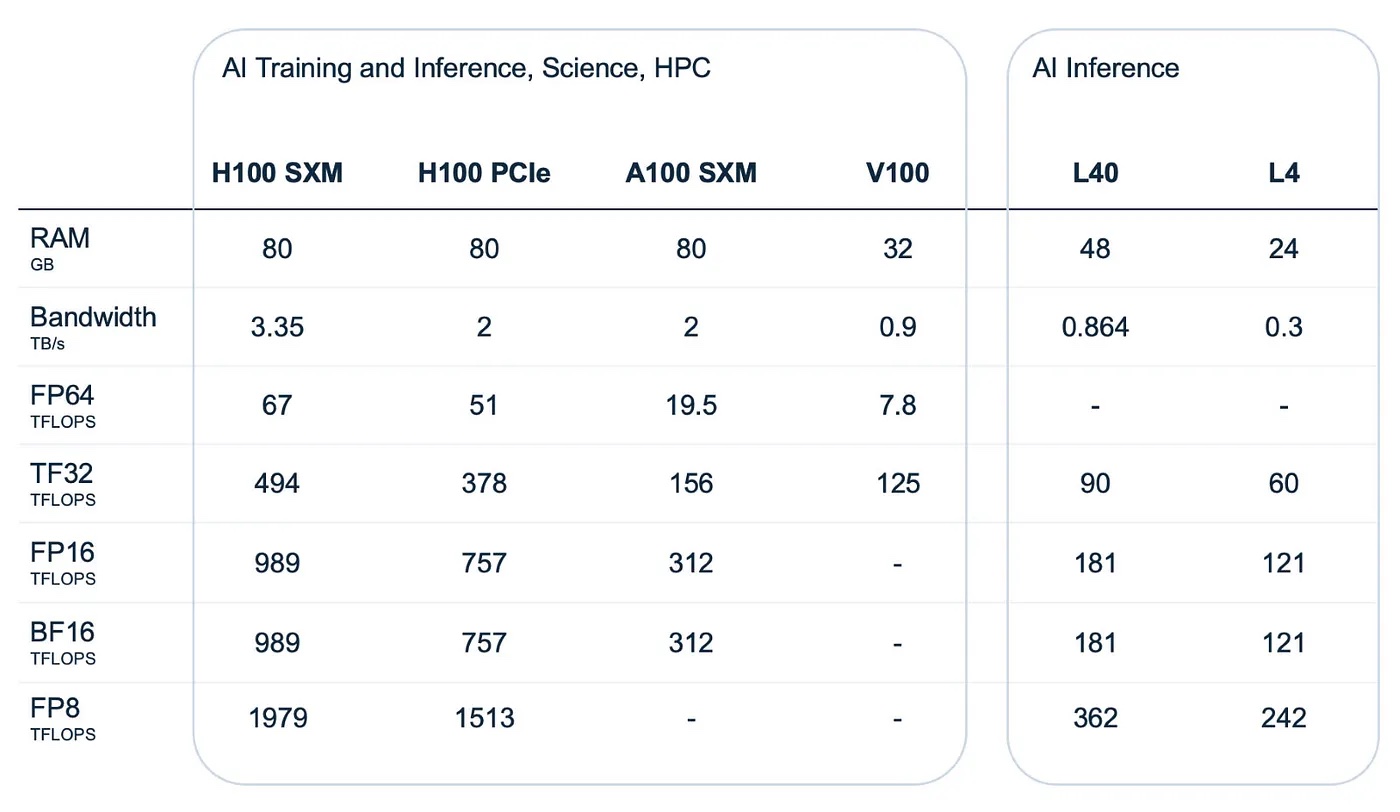
Source: NVIDIA materials
Pay particular attention to the first two rows: the amount of RAM and its bandwidth. An ML model must fit snugly into the GPU accessible to the runtime environment. Otherwise, you’ll need multiple GPUs for training. During inference, it’s often possible to fit everything on a single chip.
Let’s refresh the distinction between the SXM and PCIe interfaces. Our colleagues at NVIDIA differentiate them simply based on the servers you or your cloud provider already have. If your setup includes standard servers with PCI slots and you don’t want to invest in specialized machines where the GPU is soldered directly to the board (which is what SXM embodies), the H100 PCIe is your best bet. Sure, its specs may be weaker than those of the SXM version — but it’s perfectly compatible with standard compact servers. However, if you’re looking to build a top-tier cluster from scratch and can afford it, the H100 SXM5 is a much better choice for clustering. Nebius AI’s in-house designed nodes allow you to use any of these two interface types.
Moving on, let’s examine the performance metrics of various GPUs in training and inference, with the chart based on data from Tim Dettmers’ renowned article:
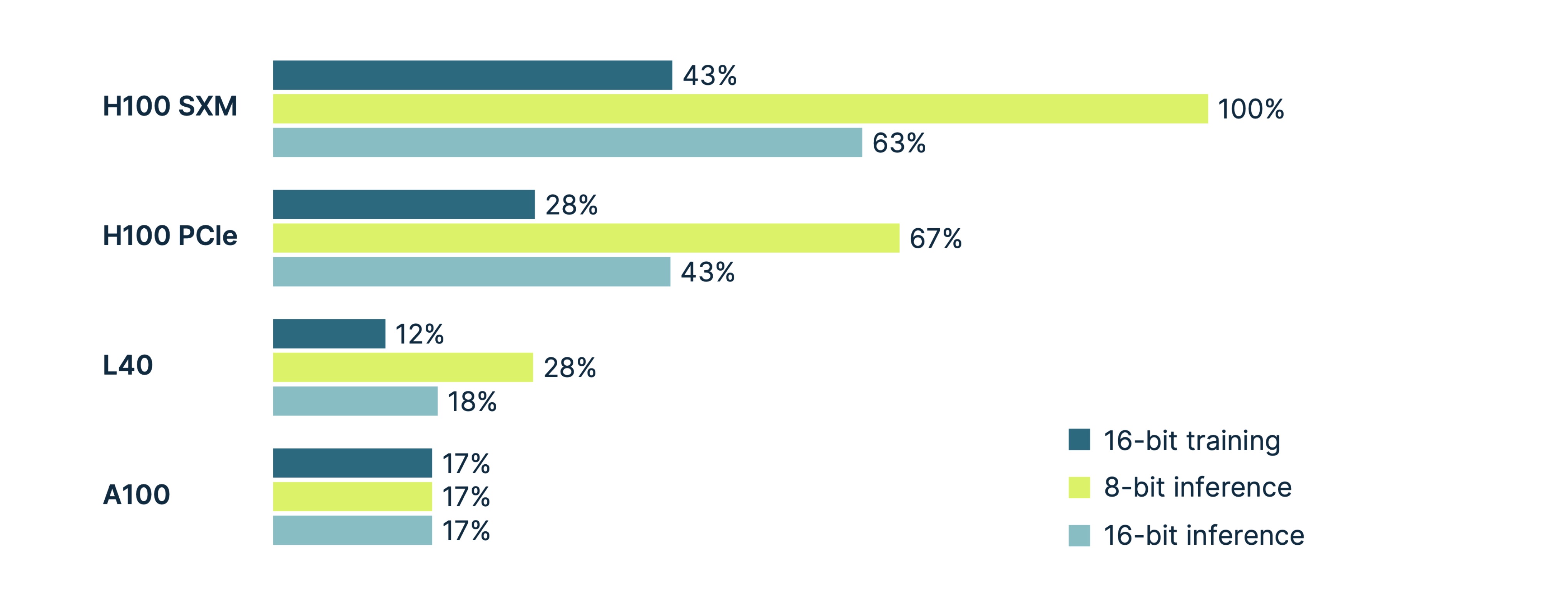
The H100 SXM metric is used as the 100% benchmark, and all others are normalized relative to it.
The chart reveals, for example, that 8-bit inference on the H100 GPU is 37% faster than 16-bit inference on the same GPU model. This is due to the hardware support for FP8-precision computing. When we say “hardware support, ” we’re talking about the entire low-level pipeline that moves data from the RAM to the Tensor core for computation. Along the way, various caches come into play. As you can see here in case with A100, 8-bit inference on such GPU doesn’t occur faster for the very reason of not supporting FP8 on a hardware level. The caches on the way from the RAM simply process numbers with the same speed as if they were in FP16 format.
For a more in-depth comparison, here’s a detailed chart from the article above:
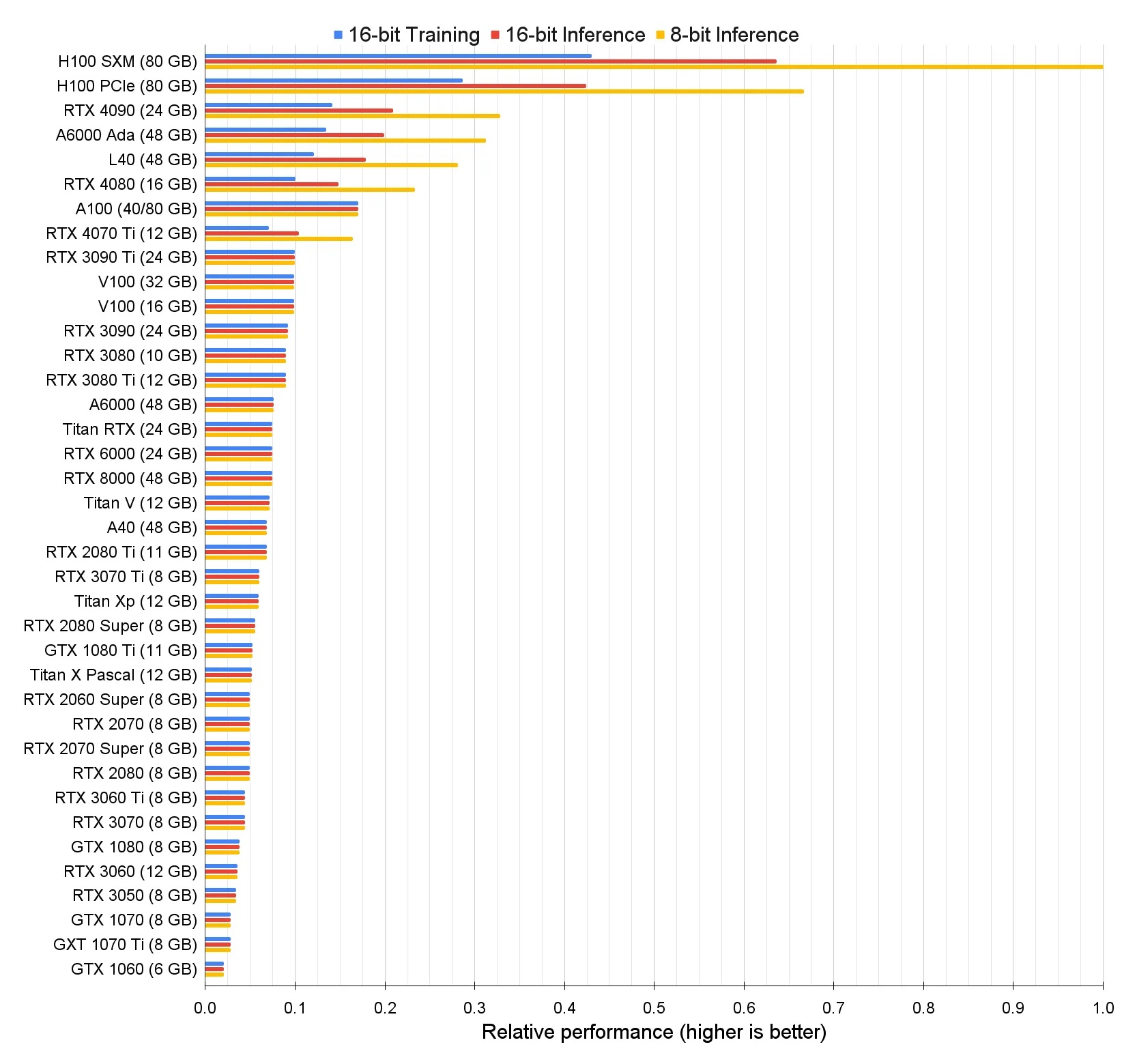
Here you can notice that the results of some RTX video cards in AI tasks are also decent. Typically, they are released with less memory than specialized cards and do not support clustering, but they are much more affordable. It makes sense to consider them if you plan on-premise infrastructure for internal experiments. However, the use of such cards in data centers is directly prohibited by the GeForce driver EULA. Therefore, no cloud provider has the right to use them in their services.
Now, let’s also compare GPUs in tasks related to graphics and video processing. Here are the key specifications relevant to such use cases:
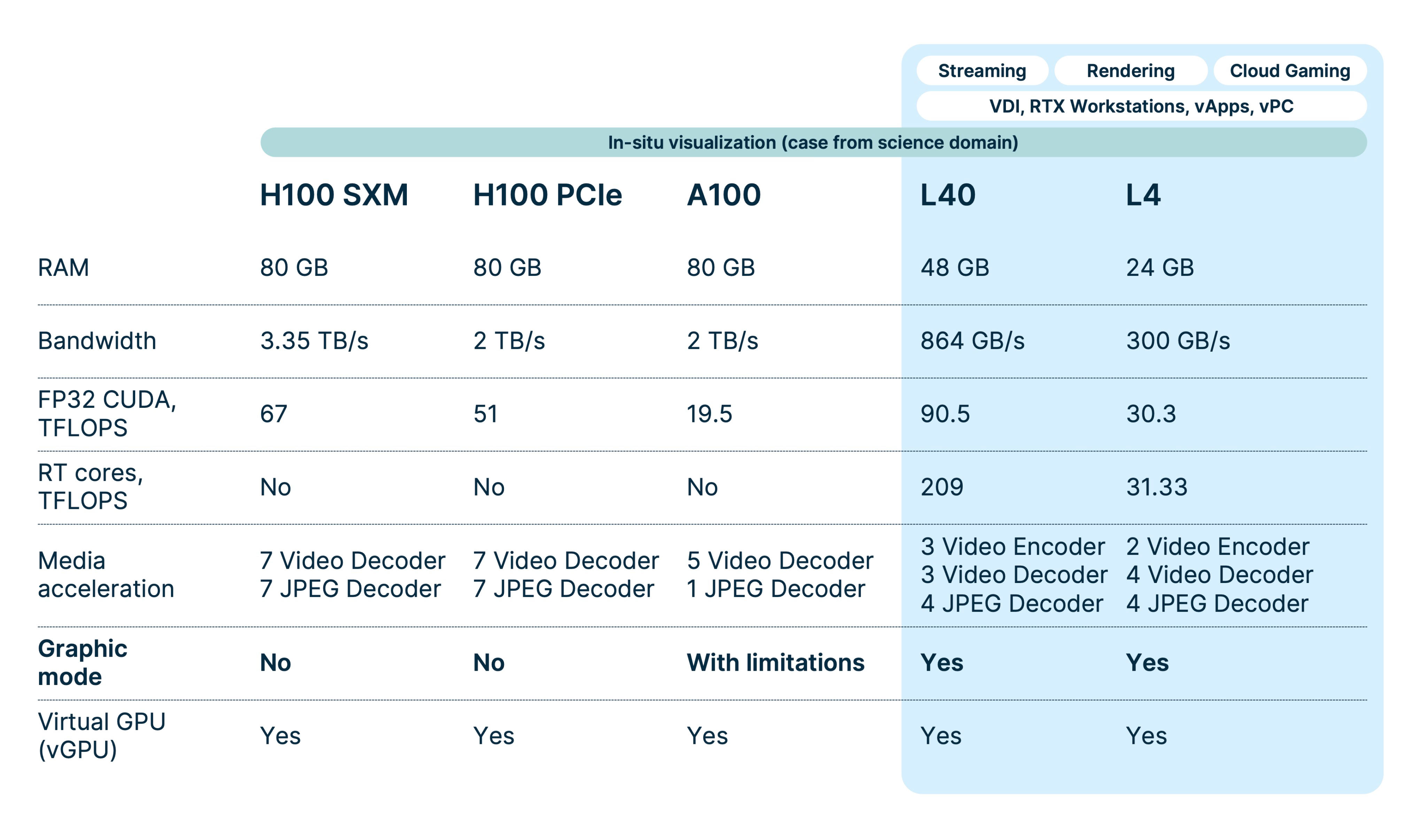
Sources: own Nebius research and NVIDIA materials
Focus once again on the RAM size and bandwidth. Also, take note of unique performance metrics for RT cores and the decoders and encoders count — these specialized chips are responsible for compressing and decompressing video feeds.
The “Graphic mode” row indicates whether a GPU can switch to a graphics-oriented mode (WDDM). The H100 lacks this feature entirely. The A100 has it, but not without limitations, making it a possible option but not necessarily practical. In stark contrast, the L4 and L40 GPUs come equipped with this mode, positioning them as versatile cards for a variety of tasks, including both graphics and training. Some NVIDIA materials even market them as graphics-oriented cards first. However, they’re also well-suited for ML and neural network training and inference, at least without any hard technical barriers.
For users, these figures mean that both H100 variants, as well as the A100, aren’t cut out for graphics-centric tasks. The V100 could potentially serve as a GPU for virtual workstations that handle graphics workloads. The L40 is the undisputed champion for the most resource-intensive 4K gaming experiences, while the L4 supports 1080p gaming. Both of these cards are also capable of rendering video at their respective resolutions.
Final overview
We’ve now arrived at our main comparison table, which showcases the characteristics of different graphics cards based on the purpose for which they were designed:
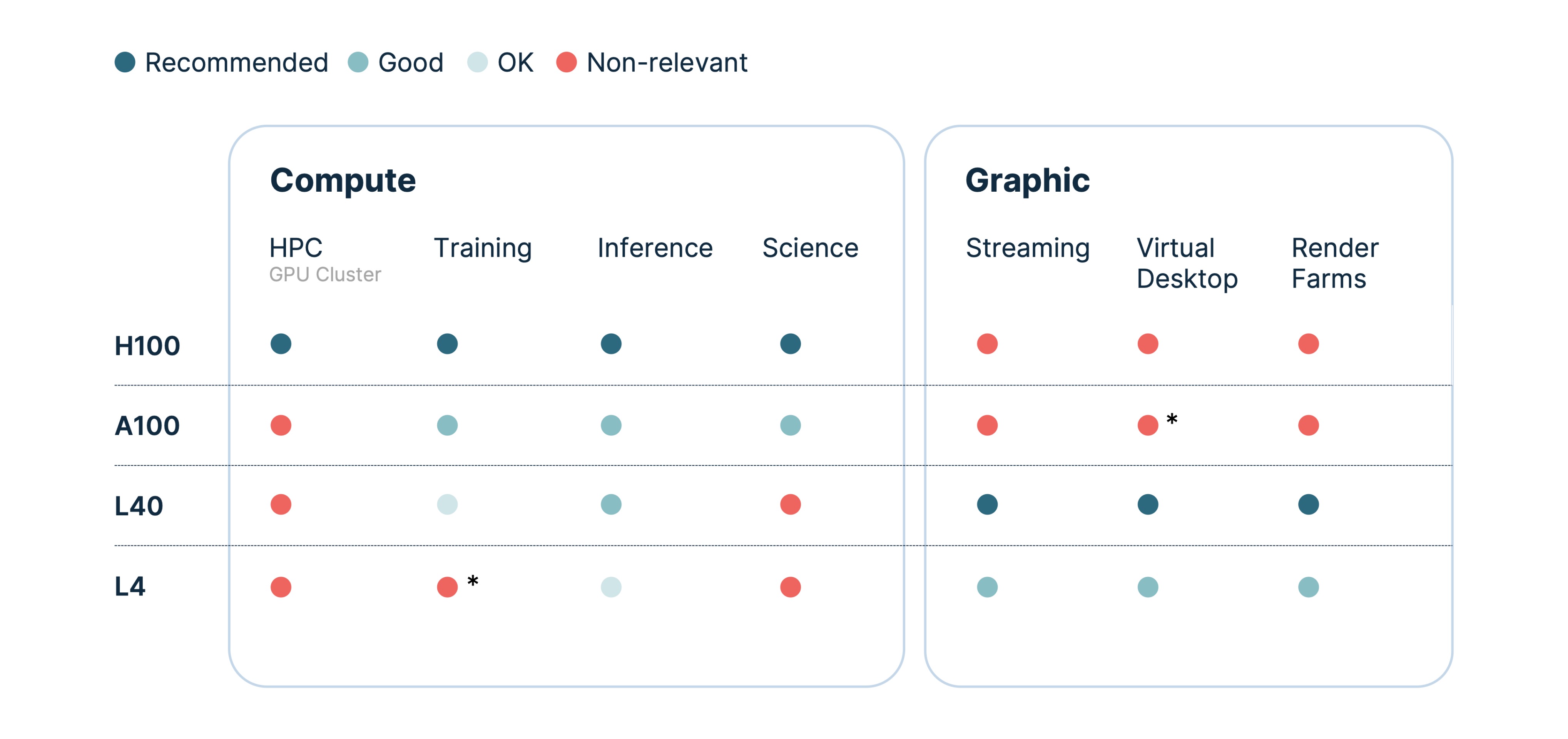
﹡ There are no technical limitations, but economically it doesn’t make sense. Sources: own Nebius research, NVIDIA materials, and Tim Dettmers’ article
From this table, we can discern two primary use case categories: tasks that focus purely on computation (labeled “Compute”) and those that incorporate visualization (labeled “Graphic”). To reiterate, the A100 and H100 are entirely unsuitable for graphics, while the L4 and L40 are tailor-made.
At first glance, you might assume that the A100 or L40 would be equally good at inference. However, as we unpacked earlier in our section on the transformer architecture, there are nuances to consider.
The column labeled “HPC” indicates whether multiple hosts can be merged into a single cluster. In inference, clustering is rarely necessary — but that depends on the model’s size. The key point is ensuring that the model must fit into the memory of all the GPUs on a host. If a model oversteps this boundary, or if the host can’t accommodate enough GPUs for their combined RAM, then a GPU cluster is required. With the L40 and L4, we are limited in scalability by the capabilities of an individual host. The H100 and A100 don’t have that limitation.
So, which NVIDIA GPU should you use in your ML workloads? Let’s look at your options:
-
L4: An affordable, general-purpose GPU suitable for a variety of use cases. It’s an entry-level model serving as the gateway to the world of GPU-accelerated computing.
-
L40: Optimized for generative AI inference and visual computing workloads.
-
A100: Offers superior price-to-performance value for single-node training of conventional CNN networks.
-
H100: The best choice for BigNLP, LLMs, and transformers. It’s also well-equipped for distributed training scenarios, as well as for the inference.
Graphics scenarios can be categorized into three groups: streaming, virtual desktops, and render farms. If no video is being fed to the model, then it’s not a graphics scenario. That would be inference, and such tasks are best described as AI video. It’s possible for a card to handle an encrypted video feed, and the A100 GPUs come equipped with hardware video decoders with such a task in mind. These decoders convert the feed to a digital format, enhance it using a neural network, and then pass it back. Throughout this process, no visual content appears on a monitor, so while the H100 and A100 can adeptly train models associated with video or images, they don’t actually produce any video. But this is a different story worth its own article.
Nebius AI offers GPUs from NVIDIA’s latest lineup — the L4, L40, and H100, along with the last-gen A100, all being located in our data center in Finland. You can use them to train ML models, run inference, and fine-tune through a variety of platform components, including Managed Kubernetes, cloud Marketplace, and more. I hope this deep dive has shed light on the best graphics card choice for your endeavors, underscored the importance of proactive decision-making in choosing GPUs, and highlighted the role of ML model architecture.