
Tips and tricks for performing large model checkpointing
There are various aspects to optimize when training large models. It often lasts weeks and involves managing billions of rows of data, with checkpoints of such models weighing terabytes in some cases. Let’s explore how to handle large model checkpointing.
To make your processes around checkpoints more efficient, we’ll discuss multiple strategies — including asynchronous checkpointing, choosing the proper storage and format, adjusting your code to the network parameters, and scheduling with possible redoing kept in mind. But first, there are some basics to consider.
Model checkpointing in a nutshell
A model checkpoint is a saved version of a model at a specific point in time. A checkpoint includes metadata, often as a JSON or YAML, and the training state in some binary format. The training state encompasses both the model parameters and the optimizer state. Checkpoints are saved periodically throughout the training process according to a predefined schedule. This is done to enable recovery from failures during training and, ultimately, to save the trained model.
Saving and loading checkpoints is a crucial component of any ML framework. For instance, PyTorch utilizes torch.save to save a Pickle-serialized dictionary containing the model’s weights and torch.load to retrieve them. TensorFlow offers several IO formats, such as .keras, .ckpt, and .h5. Flax, a deep learning framework based on JAX, recommends using orbax.checkpoint for checkpointing, but there is also flax.serialization for basic serialization tasks. In addition to the core save/load operations, some libraries offer more advanced checkpointing techniques, such as PyTorch Lightning’s checkpointing utils and the mentioned orbax.checkpoint for JAX.
What is so special about large models checkpointing
The number of parameters in a model directly affects its checkpoint size. Essentially, a parameter is just a number, typically saved as a float32 data type, i.e., 4 bytes per number. Furthermore, modern neural networks are trained using adaptive optimizers, which attach optimizer statistics to each model parameter. For example, the Adam optimizer adds two additional float32 statistics for each model parameter. So, 12 bytes must be saved for each model parameter. Keep in mind that:
-
When performing inference, the optimizer state is not needed, and model parameters can be saved as a 16-bit (e.g., float16 or bfloat16) data type without a loss of prediction accuracy. That is, only 2 bytes per parameter are required for inference, which is 1/6 of the checkpoint size in training format. One can go further and apply 8-bit or even 4-bit quantization.
-
Basic optimizers, such as stochastic gradient descent (SGD), do not maintain state, but they are not powerful enough to train deep models.
Classic machine learning models like logistic regression or gradient boosting have at most hundreds of thousands of parameters, resulting in checkpoint size of no more than several megabytes. Deep learning models, such as BERT, may have millions of parameters and weigh several gigabytes. However, saving and loading even a couple of gigabytes is not a significant challenge for modern hardware.
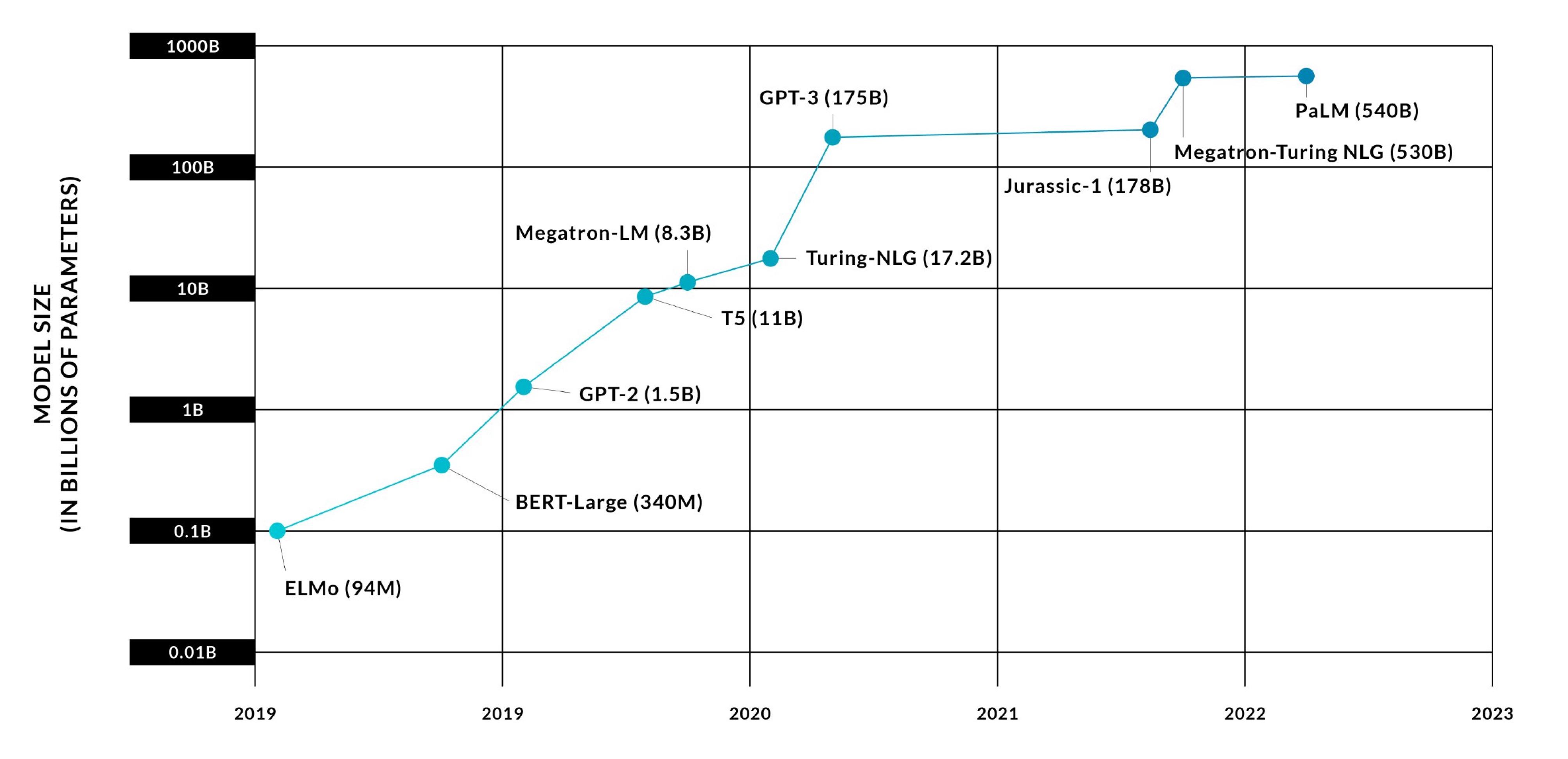
Large language models such as LLaMa range from 1.3 billion (1.3 * 10^9) to 70 billion parameters, while GPT-3 boasts a staggering 175 billion parameters. How large are their checkpoints? Let’s quickly calculate the size of LLaMa 7B checkpoint in inference format saved with float16 data type:
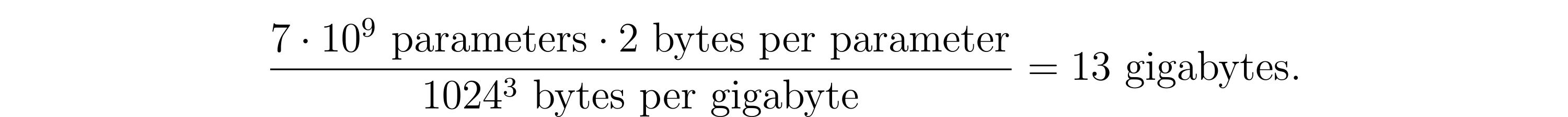
In training format, it reaches ~69 gigabytes if saved with optimizer state and parameters in float32. Finally, LLaMa 70B model checkpoint in training format is 782 gigabytes in size.
Moreover, large language models are often trained on several GPUs (single-host) or even on clusters of GPU-equipped machines (multi-host). A number of hosts need to load the same copy of a model from storage, thus creating a huge load on the storage. The training state could be sharded among hosts, necessitating special logic to load and save checkpoints.
How to handle large model checkpointing
Use async checkpointing
Throughout training, model parameters reside in GPU memory (VRAM), but saving a model to storage is a task for the CPU, requiring the model parameters to be stored in RAM. Consequently, two steps are necessary to save a checkpoint. First, the parameters are offloaded from VRAM to RAM — this is quite fast. Second, the parameters are saved from RAM to storage — this process is slower and can take minutes or even tens of minutes, depending on the model size and storage throughput.
Here is a trick: once the parameters have been offloaded from VRAM to RAM, we can proceed with model training on the GPU while the CPU saves the checkpoint to storage in the background. This is called asynchronous checkpointing. It has already been implemented in some frameworks, such as AsyncCheckpointIO in Torch-Lightning and AsyncCheckpointer in orbax.checkpoint.
Keep in mind that the host’s RAM size should be large enough to store the checkpoint in memory. Also, do not forget to wait for the background saving process to finish at the end of the training.
Know your storage
While your laptop uses just a physical SSD/HDD unit, cloud providers like Nebius AI offer a number of storage services: network disks, network file storage (NFS), object storage. Please note: although the data ultimately gets written to the same bare-metal HDDs/SSDs, there could be entirely different cloud logic behind those storage services. Each option comes with its pros and cons, including differences in IO speed and features. Let’s review them in detail.
Network disks
Cloud allows us to easily scale our VMs or seamlessly relocate a VM from one host to another. However, this would not be possible with regular disks because we can’t move data from one disk to another instantly. That’s why the cloud uses network disks. Although a network disk appears like a regular disk (e.g., /mnt/my-disk), it is actually a remote 'service' accessed over the network. A network disk cannot be mounted to more than one VM at a time. Thus, they can’t be used out of the box to share the same checkpoint between multiple hosts.
The network file system (NFS) is a go-to alternative for a file system that, in contrast, can be shared by multiple hosts.
P. S. Some cloud providers also support dedicated hosts with local (non-network) disks, but this is quite unusual.
Network file system
NFS itself is a protocol, and the actual storage implementation depends on the cloud provider. For instance, in Nebius AI, one can use a higher block size and SSD disks to achieve better NFS performance. If one wants to gain more control over NFS, there is an option to deploy a self-managed NFS (for example, GlusterFS) on top of network disks and VMs.
S3-compatible object storage
Object storage is not a file system!
Object storage is cheap and convenient. However, it is crucial to understand that it is not a file system. Object storage simply stores a mapping of 'string key -> binary data.' Although it may seem like a file system from the UI perspective, with directories and sub-directories, this structure is just for the user’s convenience. For example, object storage does not support fast atomic move (mv) operations: mv creates a copy of the data and then removes the old data. It is impossible to overwrite some bytes in place. Also, symlinks/hardlinks are not supported in object storage.
Note: some object storage implementations may support more advanced logic, such as atomic mv operations or hierarchical namespaces, so it’s better to check the documentation.
Parallel IO
Object storage is optimized for parallel reads and writes. It supports reading a random byte range from a blob. Thus, make sure that your code performs parallel IO with object storage. For example, aws s3 cp does parallel IO, and boto3’s client.copy also does it.
s3fs
A number of tools exist to mount an S3-compatible bucket as a volume (e.g., mount my-bucket at /mnt/s3/my-bucket). Examples of such tools include s3fs, Goofys, and mountpoint-s3. They are really convenient because they allow the end-user to abstract away from S3 specifics and simply use an S3 bucket as a local directory. Yet, as it was mentioned above, S3 is not a file system and is optimized for parallel IO. Thus:
-
The standard mv takes a lot of time and should be avoided.
-
cpmight be less performant than S3-specific tools. Double-check that your s3fs performs parallel IO and that the s3fs mount parameters are optimal. That is,aws s3 cpandcphave similar performance. -
S3 doesn’t have a concept of a directory, so any check like
directory.exists()is ambiguous and defined by s3fs implementation. To give you context, some s3fs implementations assume that any directory exists, while others will check that there are objects with the given prefix, i.e., check the output of ls. -
Due to S3 being a key-value storage rather than a file system, metadata requests (e.g.,
lsandfind) might be slower and not that efficient, so make sure your code doesn’t abuse these commands. Otherwise, S3 may start rejecting your requests with an error like '429: Too Many Requests.'
Checkpoint format matters
There are multiple ways to lay out a checkpoint on a disk. For example, torch.save produces just one Pickle-serialized blob, while others may save each layer to its own file. From a storage point of view, reading 10 GB as one big file might not be the same as reading 100 files of 0.1 GB each. On the other hand, one big blob makes it harder for each host to read only a subset of the data it needs.
For instance, one might be experimenting with optimal model sharding across GPUs, testing different combinations of data parallelism and model parallelism. If the checkpoint layout is sufficiently granular, each host can efficiently access only the tensors it requires. However, overly granular formats can overwhelm the storage with hundreds of small files. That’s why more sophisticated formats exist, such as OCDBT, which smartly combine multiple small blobs into larger files.
Benefit from the network in multi-host training
In a multi-host, data-parallel training setup, many hosts store the same model in memory. At the beginning of the training, all data-parallel instances must retrieve the same checkpoint. If all instances attempt to read the same checkpoint from storage simultaneously, they generate a significant load on the storage system. Imagine a situation when 32 hosts read a 100 GB checkpoint at the same time — that is 3.2 TB to transfer over the network.
The performance in this case depends on storage’s ability to scale.
-
If a storage has a fixed bandwidth, it will be shared by all readers. Thus, each host will get only a fraction of the bandwidth and read multiple times slower, for example, 32 times slower.
-
If a storage is scalable, it will automatically adjust to the load, allowing each reader to maintain a constant reading speed.
If storage with fixed bandwidth is used, or if a storage system does not scale well, the following method can be employed: one host can read the checkpoint into memory and then share it with other hosts via the inter-cluster network. From an implementation standpoint, it could be NCCL Broadcast.
If one utilizes a GPU cluster with InfiniBand support, it is possible to load a checkpoint into GPU memory and feed it directly into GPUs on other hosts via an ultra-fast GPU-to-GPU network.
If the checkpoint is sharded, IO can be parallelized even further, so that each host reads only a part of the checkpoint, and then NCCL AllGather is used to collect shards from different hosts. Some checkpointing frameworks already have this feature implemented — orbax.checkpoint comes to mind yet another time. The same optimization can also be applied to multi-host checkpoint saving, where each host saves only a portion of the checkpoint. Again, orbax.checkpoint has this functionality out of the box.
Choose a sane checkpointing schedule
A checkpointing schedule is a logic such as 'save a checkpoint every N steps and store the last M checkpoints.'
Checkpointing frequency
Imagine the training crashes and intermediate progress is lost. Upon restarting the training from the last saved checkpoint, some steps will need to be redone. Therefore, the choice of checkpointing frequency represents a trade-off between 'redoing more steps after a restart to restore progress' vs. 'longer training time due to GPU-blocking part of saving.' For instance, saving a checkpoint every five minutes might be excessive, but saving one every hour could be reasonable, especially if the training spans days and restarts are rare.
Storing more than one checkpoint
It’s not necessary to store every intermediate checkpoint; however, keeping some of them can be advantageous. For example, consider storing several previous checkpoints and some others from the past: for example, from yesterday. Why? Imagine there’s a gradient explosion; then, you might want to tweak the hyperparameters and restart the training from a previous checkpoint. If you’ve spotted a gradient explosion too late and the last checkpoint is already corrupted, you would have to start over from the beginning if only the latest checkpoint is stored. Keep in mind, though, that while storage costs are significantly lower than those of GPUs, they are not negligible.
