Sources: Tim Dettmers, MLCommons

Which GPUs should you choose for CV?
In the field of computer vision, selecting the appropriate hardware can be tricky due to the variety of models and their different architectures. Today’s article explores the criteria for selecting the best GPU for CV.
May 7, 2024
6 mins to read
Models that are currently prominent in the field include ResNet-50 and various vision transformers (ViTs). ResNet, while not a new model, continues to be relevant due to its deep architecture, which enables it to perform well on a variety of computer vision tasks. ViTs, in turn, were initially successful in natural language processing but then have also been adapted for computer vision tasks. Such models are being used for image classification and other tasks due to their ability to handle long-range dependencies within the data. The most popular ViTs include:
- YOLO (You Only Look Once). These models, especially the latest versions like YOLOv8, are at the forefront for real-time object detection tasks. They are known for their speed and precision, making them suitable for applications needing fast and accurate object detection. Check out this guide by OpenCV.ai to learn more about the YOLO family of models.
- DINOv2: This is a self-supervised learning technique developed by Meta to train high-performing CV models. It lessens the dependence on large annotated datasets, showcasing the strength of self-supervised methods.
Criteria for selecting a GPU
While in choosing a computer vision GPU, we obviously aim to maximize the golden trio of characteristics, which are VRAM, core performance measured in FLOPS, and memory bandwidth, some additional gains can be achieved by considering more detailed aspects:
- For real-time video stream decoding (e.g., from IP cameras), where every millisecond is critical, GPUs equipped with NVDEC/NVENC chips are essential.
- When examining the characteristics of a particular GPU, computer vision experts should pay attention to the model weight format and the chip’s hardware support for this format. For instance, despite being somewhat outdated, training ResNet-50 in FP32 precision still makes sense, which means NVIDIA V100 can be considered for both training and inference. Refer to this article for a better understanding of different precisions. Models from the ViT class are often trained in two other formats:
- If in FP16, then there’s no speed gain on V100 compared to FP32.
- If in BF16, then V100 cannot be used at all as they’re not compatible.
- It is also important to explore the best interconnect options for your specific machine-learning scenario. In other words, try to understand how quickly you can fetch data to GPU for processing. There are three common types of workload here:
- Single GPU or multiple chips are not interconnected. In this case, the graphic card doesn’t need to communicate with other GPUs to do its job. Such setups are often built for inference, where the speed of RAM → VRAM → GPU pipeline and back is crucial. The speed of the RAM → VRAM segment is determined by the PCIe bus speed and the processor’s ability to load this bus. A GPU characteristic known as GPU memory bandwidth defines the speed at which the computational cores can access video memory. The higher it is, the better, since such bandwidth often becomes the bottleneck, not the FLOPS (performance of the GPU’s computational cores).
- Multi-GPU. We use multiple GPUs for a single task but don’t exceed the limits of one server. These scenarios apply to both training and inference. We face overheads from GPU communication with each other. Either this communication is conducted over the PCIe bus, which is slow and often becomes a bottleneck, or the GPUs are connected by a high-speed NVLink, and then we’re good.
- Multi-node (or multi-host). The workload is spread across several hosts. GPUs on different hosts must communicate over the network, complicating the path: RAM → VRAM → GPU → VRAM → RAM → NIC → switch → (a route dependent on many factors) →… Here, InfiniBand clusters become relevant, possessing technologies aimed to speed up and shorten this path. For example, data can be transferred directly from VRAM to NIC.
Types of GPUs for CV
Entry-line
The most affordable data center NVIDIA GPUs, like L4 or consumer cards such as those in the GeForce RTX series, demonstrate a good balance between price and performance for individual data scientists and small-scale projects.
Professional
For medium to larger workloads, professional GPUs like the NVIDIA RTX 6000 Ada or NVIDIA L40S provide a more stable and professional experience, thanks to the amount of video RAM, memory access speed (bandwidth), and a wide range of support for precision in floating-point numbers.
Large scale
At the peak of AI company’s deployments, NVIDIA’s Hopper and the latest Blackwell families stand at the forefront of GPU technology, delivering unmatched processing power for the most demanding computer vision applications. The main advantage of these cards lies in their capability to be combined into computing clusters with a large number (tens of thousands) of chips. And don’t brush off previous models such as the A100 and even the V100 — as mentioned earlier, Volta is still suitable for some tasks.
Benchmarks
We’ll provide some basic reference numbers relevant to the CV domain. To explore a wider variety of graphics cards and models, take a look at the detailed overview.
ResNet at FP32
Here, the MLPerf demonstrates the GPU performance during model training.
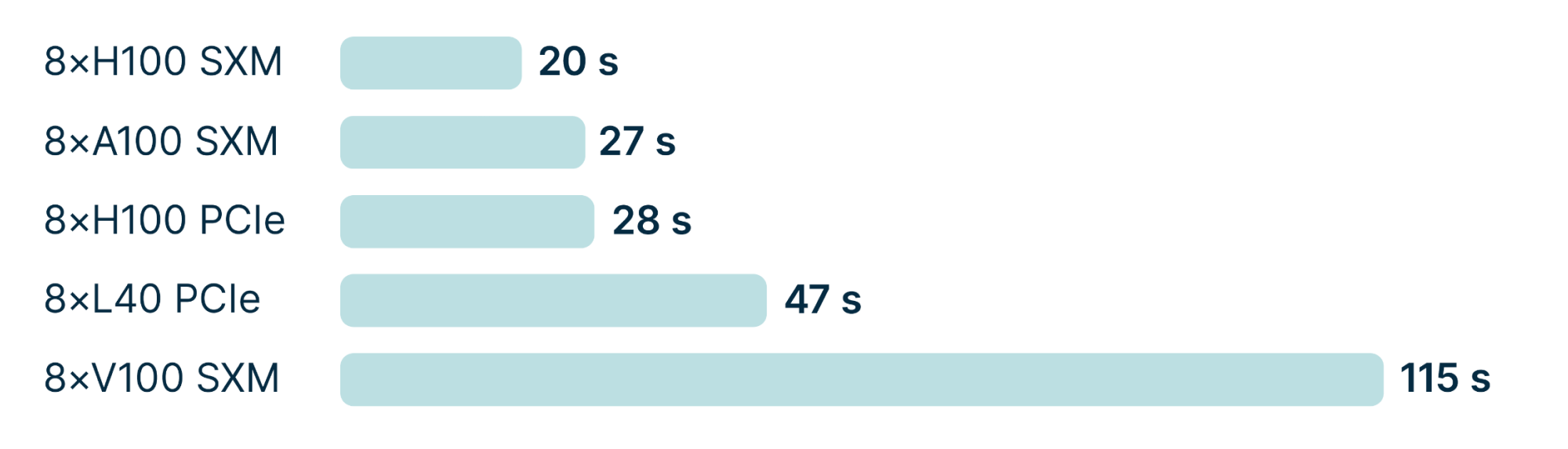
Transformers
Below, you can see the raw relative Transformer performance of GPUs. For example, an A100 SXM has about 0.4x the performance of an H100 SMX for 16-bit training. In other words, an H100 SXM is 2.5 times faster for 16-bit training compared to an A100 SXM.
We can also see that there is a gigantic gap in the 8-bit performance of H100 GPUs and old cards that are optimized for 16-bit performance.
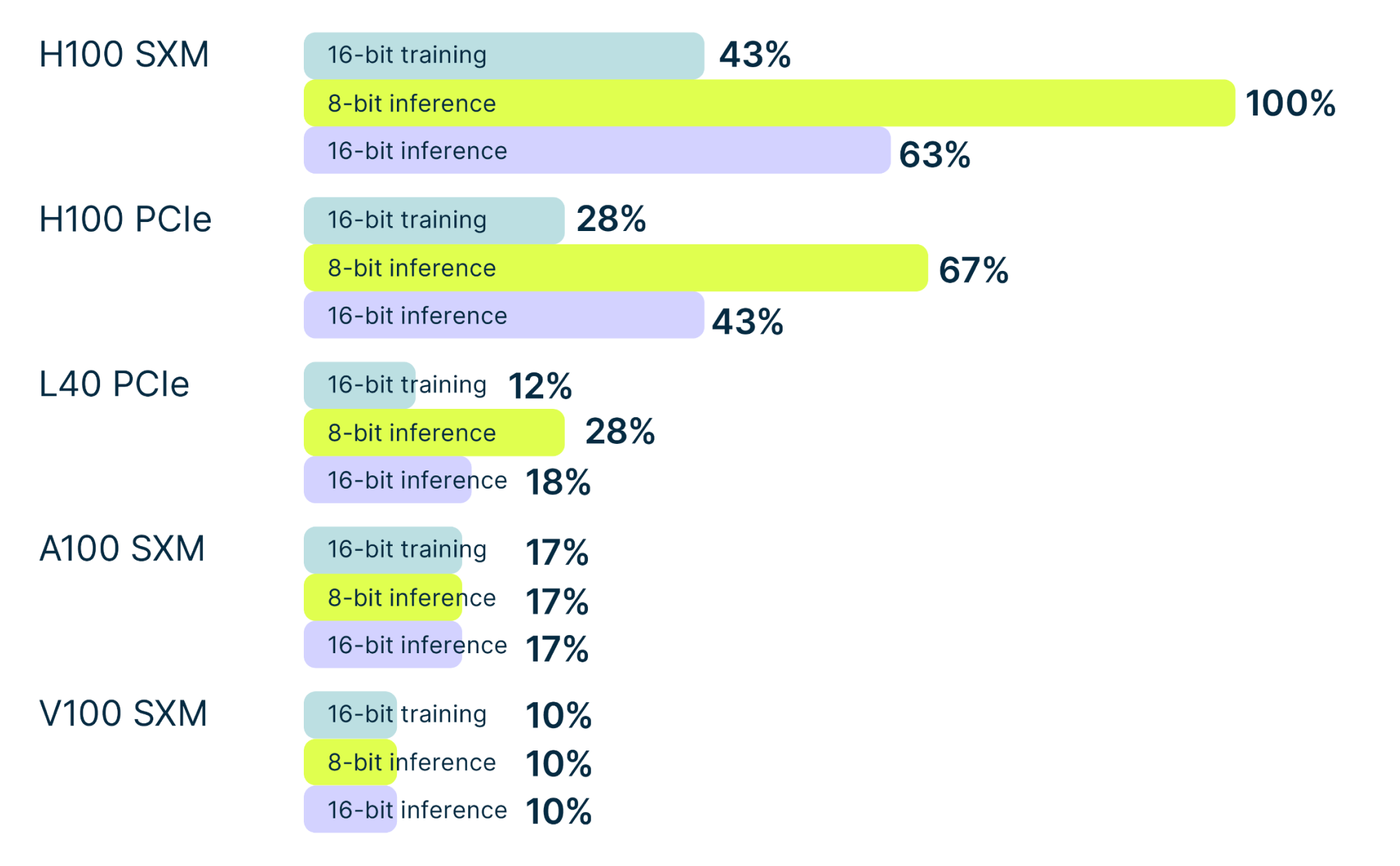
Source: Tim Dettmers
Recommendations
As a cloud provider, Nebius AI operates the data center line of GPUs.
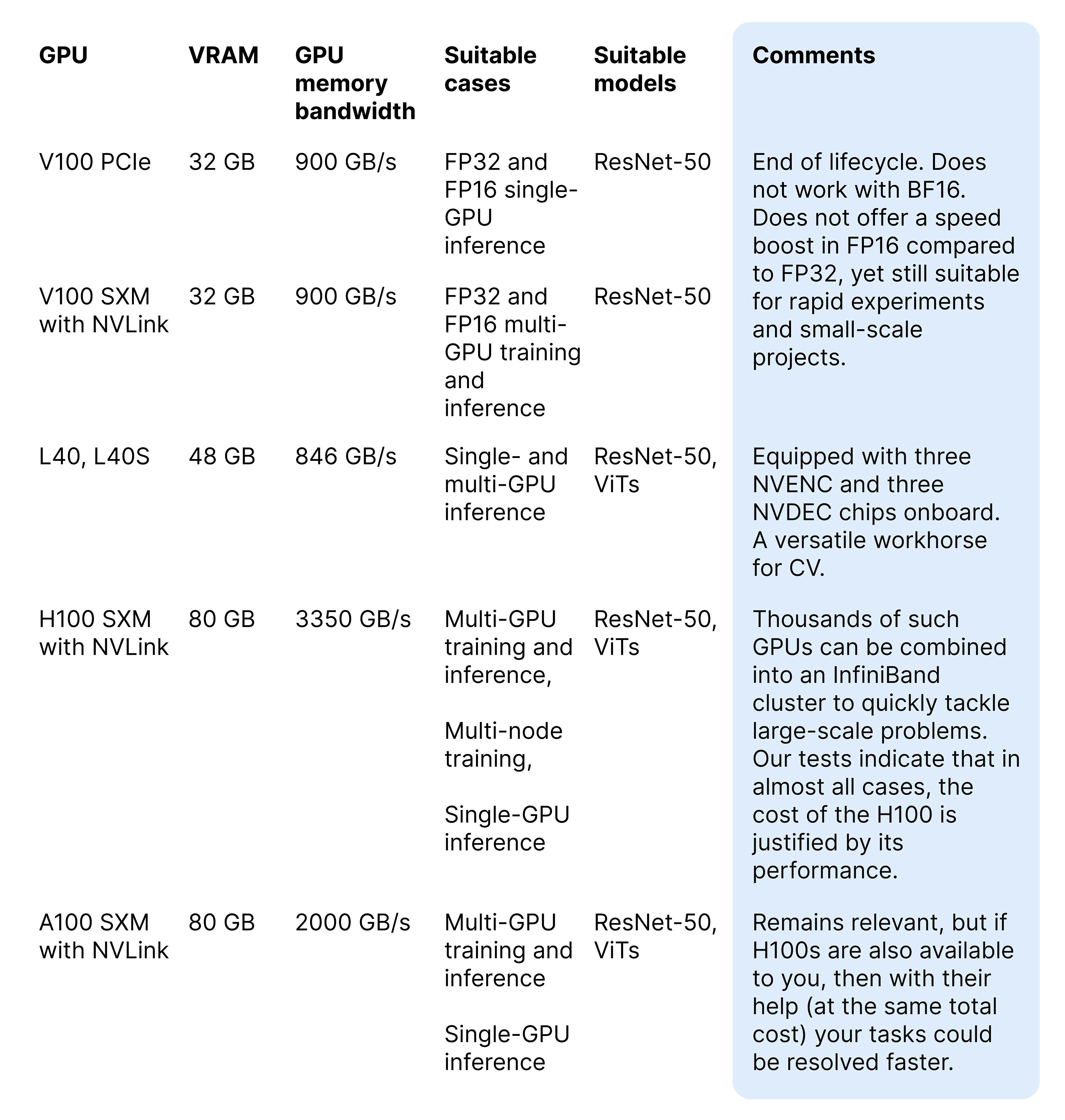
Sources: own Nebius AI research and NVIDIA’s materials
While inventing and advancing in the subfield of GPU-accelerated computer vision and image processing, try to understand the essence of emerging tasks. Match the logic of algorithms with the principles of operation of graphics cards and surrounding infrastructure. Developers of these low-level technologies kept in mind some frequent cases during their R&D, so you just have to follow their line of thinking. That’s how you make your pipelines of computer vision tasks cost-efficient and productive.
Explore Nebius AI
