
How Dubformer performs AI dubbing on Nebius infrastructure

Content localization made easy
In a world of media content production, breaking language barriers is a significant challenge. AI localization, as developed by Dubformer, stands out as the only viable solution.

AI dubbing technology
To thoroughly understand the technology that powers Dubformer, let’s look at it step by step.
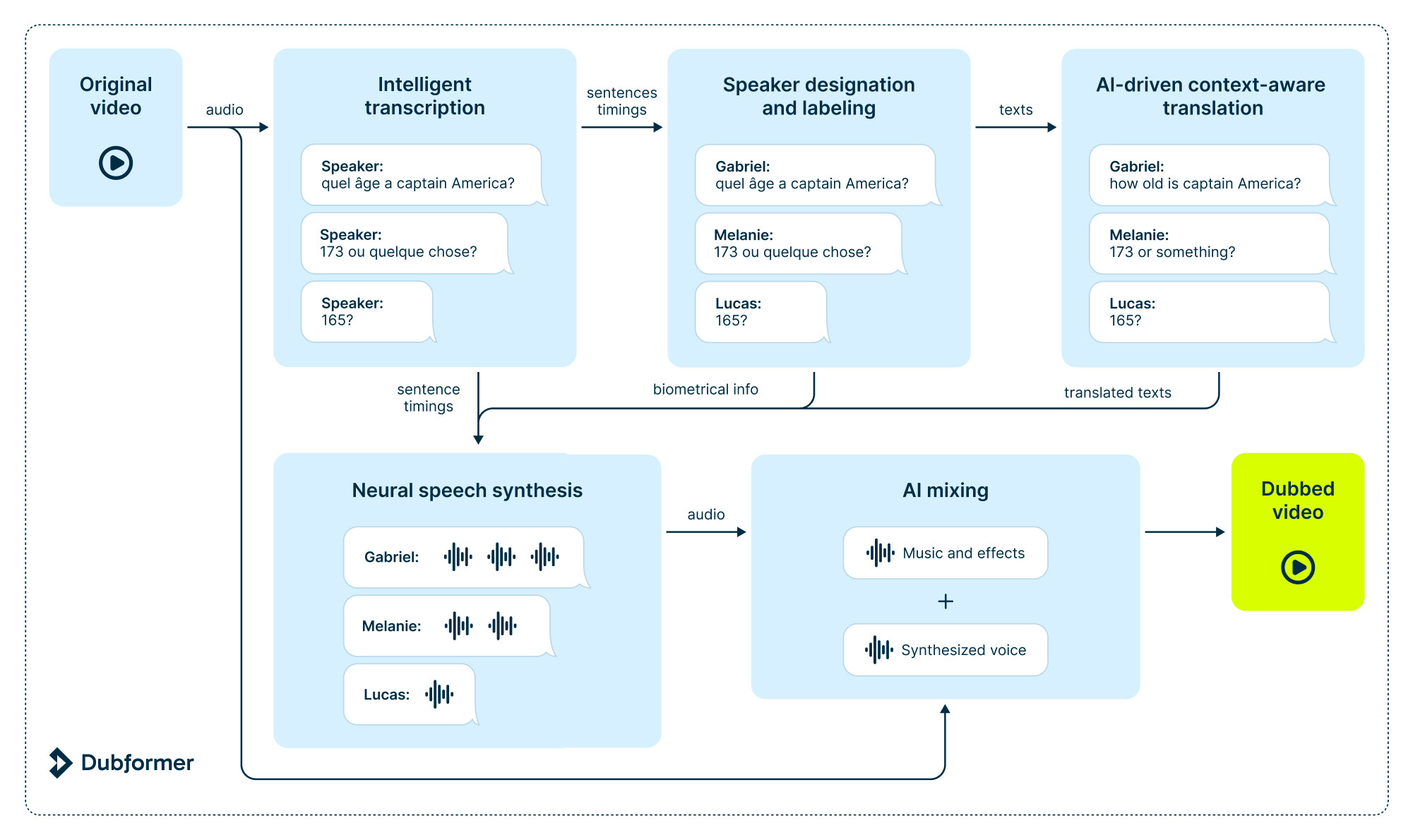
Step 1. Intelligent transcription
Transcription quality plays a crucial role in content localization. Dubformer’s AI models recognize speech, structure words into sentences, and insert punctuation, all while accounting for context and intonation.
Step 2. Speaker designation and labeling
In multi-speaker videos, identifying who said what is essential for preserving the intended meaning. This is done by Debformer’s specialized algorithm.
Step 3. Context-aware translation
High-quality subtitle translation isn’t just about looking at isolated sentences. Dubformer’s translation neural networks must also ensure accurate flow, consistency, and contextual understanding.
Step 4. Neural speech synthesis
Dubformer doesn’t stop at subtitles: the company uses its own neural dubbing technology to deliver studio-quality voice-overs. Here, the algorithms eliminate the original voices and select appropriate voices for the dubbing track, ensuring a seamless auditory experience.
Step 5. AI mixing
To achieve broadcasting-level quality, it is necessary to integrate the synthesized audio into the final track. This involves working with the music and effects (M&E) track or utilizing AI to generate one in a process called smart voice removal. Dubformer also automatically adjusts volume balance and aligns the result with industry standards.
Human touch
While machine translation technology can be impressive, it isn’t flawless. For example, when a character in an English-language film suddenly switches to Latin, the AI algorithms can get confused.
Recognizing these limitations, Dubformer uses a human touch model, incorporating professional translators and native speakers to verify each localization step. This approach ensures unparalleled precision, particularly in nuanced scenarios like the one we mentioned.
As you might guess, Dubformer’s AI models require substantial GPU computing power and significant storage capacity to store training data.
Let us build pipelines of the same complexity for you
Our dedicated solution architects will examine all your specific requirements and build a solution tailored specifically for you.

How speech synthesis and recognition work
To train its models, Dubformer employs a fleet of virtual machines maintained within the Nebius AI infrastructure through the Compute Cloud service. Some machines come equipped with NVIDIA A100 Tensor Core GPUs, while others are outfitted with the even more powerful H100s.
High-performance graphics cards are essential for training complex speech synthesis and recognition models — integral parts of Dubformer’s product. A massive volume of data must be loaded into each GPU’s VRAM to train these models. For a better sense of scale, consider this: speech synthesis models train on thousands of hours of audio recordings, and speech recognition models train on hundreds of thousands of hours. When it comes to data capacity, we’re talking about hundreds of terabytes — which is comparable to or even exceeds the amount of data required for LLM training. That’s too much for any virtual machine’s disk to handle. Using regular disks also goes contrary to Dubformer’s inherent need to distribute data across many VMs instead of storing it on standalone machines. Thus, any data accessed during model training or hypothesis testing is streamed to the GPUs from Object Storage — one of the key services within Nebius AI.
Dubformer models undergo training 24/7, so these compute resources are always in use. To utilize them effectively, the team at Dubformer maintains a queue of dozens of experimental tasks. Speech recognition models can take months to train — most experiments take place in voice synthesis. Hypotheses are either tested on Nebius AI’s virtual machines in parallel with production workloads or remain in the queue until their turn comes up — depending on the data volume at any given time.
The trained models themselves are not very large — they can easily fit into the VRAM of just one graphics card. Nevertheless, the team at Dubformer prefers to simultaneously use eight GPUs on an SXM board — an additional server board that connects to the motherboard. The graphics cards communicate with each other through NVLink. You can learn more about these hardware technologies in a dedicated article.
Models to perform real-time dubbing
Dubformer hosts several types of models in the cloud:
- Most of the models in speech recognition use the CTC (Connectionist Temporal Classification) algorithm, which is especially popular in audio and pattern recognition.
- Voice synthesis uses models such as VITS (variational inference with adversarial learning for end-to-end text-to-speech), FastPitch (parallel text-to-speech with pitch prediction), and a Tortoise analog, fine-tuned in-house by Dubformer engineers. The team’s goal here is that the synthesis is controllable, meaning it must be technically possible to transform the voice on the fly.
This powerful combination of computational resources of Nebius AI and Dubformer’s innovative models has led to high-quality dubbing and voice-overs, significantly reducing costs and turnaround times. This achievement has not gone unnoticed, with Dubformer’s AI-dubbed content gaining traction on television and leading OTT streaming platforms worldwide.
Nebius services used
Compute Cloud
Providing secure and scalable computing capacity for hosting and testing your projects. GPU-accelerated instances use top-of-line NVIDIA GPUs.
Object Storage
Secure, scalable and cost-effective cloud object storage. Store, easily access, share and manage large amounts of unstructured data.
Virtual Private Cloud
Providing a private and secure connection between Nebius resources in your virtual network and the Internet.
More exciting stories

Recraft
Recraft, recently funded in a round led by Khosla Ventures and former GitHub CEO Nat Friedman, is the first generative AI model built for designers. Featuring 20 billion parameters, the model was trained from scratch on Nebius AI.

Unum
In our field, partnerships that harness complementary strengths can drive significant breakthroughs. Such is the case with the collaboration between Nebius AI and Unum, an AI research lab known for developing compact and efficient AI models.