
Training a 20-billion foundational model: Recraft’s journey

Long story short
This article covers how Recraft trained a model using Nebius AI, shedding light on both companies’ challenges, the solutions they implemented and what they ultimately achieved.

Training infrastructure from Recraft’s perspective
The company utilized a considerable amount of hardware, which requires efficient management and orchestration. A widely adopted solution for this is a Kubernetes cluster. Thanks to Nebius, Recraft had access to Managed Kubernetes, which seamlessly handled the deployment of nodes, GPU drivers and beyond. Recraft’s main task was to develop PyTorch training code that operates on a particular kind of engine built upon the K8s.
In this case, this engine is Kubeflow, which automates the creation of pods and the allocation of the necessary resources. The training process also involves extensive communication between GPU nodes, of course. Like many others, Recraft uses backpropagation algorithms for neural network training, necessitating the aggregation of gradients of the network parameters across all workers in the cluster.
Here’s what the training infrastructure looks like as a whole:
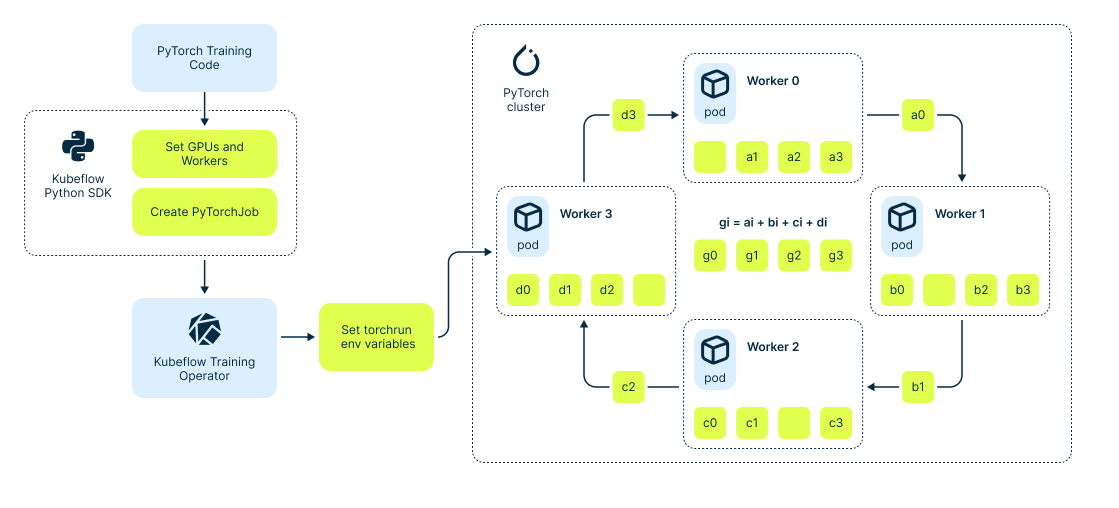
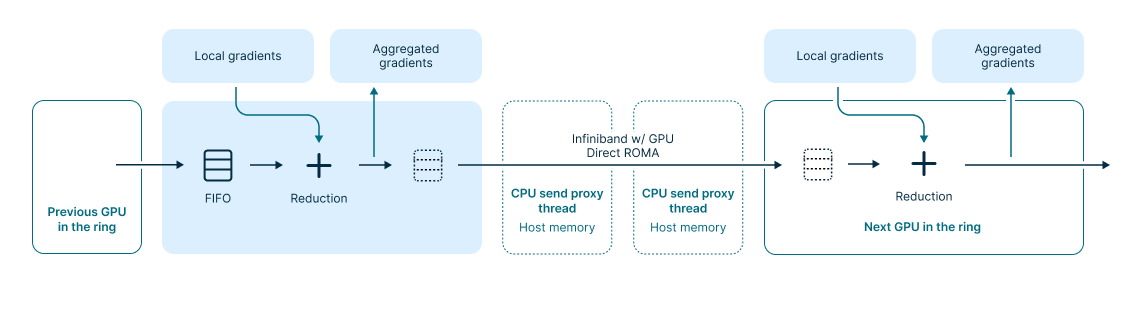
And here’s what it looks like at the hardware level:
Let us build pipelines of the same complexity for you
Our dedicated solution architects will examine all your specific requirements and build a solution tailored specifically for you.

Applying the NCCL
To implement the illustrated infrastructure, one has to understand, at least briefly, lots of low-level technologies listed here. These include the intricacies of the InfiniBand network, NVIDIA’s GPUDirect RDMA for direct GPU-to-GPU communication and some others, all of which provide the fastest possible training speeds for you.
One way to simplify this setup is by applying the NVIDIA Collective Communications Library (NCCL), which, in theory, manages numerous hardware processes automatically. It selects the most efficient communication algorithm based on the network topology of your cluster, providing a high-level API for operations such as gradient reduction from all nodes and parameter broadcasting. NCCL’s benefits include:
- Performance. The library eliminates the need for developers to optimize their applications for specific hardware configurations manually. It offers fast collective operations over multiple GPUs, both within single nodes and across multiple nodes.
- Ease of programming. Featuring a straightforward API, NCCL is accessible from various programming languages. The library also adheres to the popular collective API standards set by the MPI (Message Passing Interface).
- Compatibility. NCCL supports virtually any multi-GPU parallelization approach, including single-threaded, multi-threaded (one thread per GPU) and multi-process setups (combining MPI with multi-threaded GPU operations).
Typically, modern training frameworks such as PyTorch and TensorFlow use the NCCL internally, invoking its functions from the library.
The path is still not straightforward though. Here are several of the errors Recraft’s team faced while building infrastructure for the distributed training, all unclear and hard to debug:
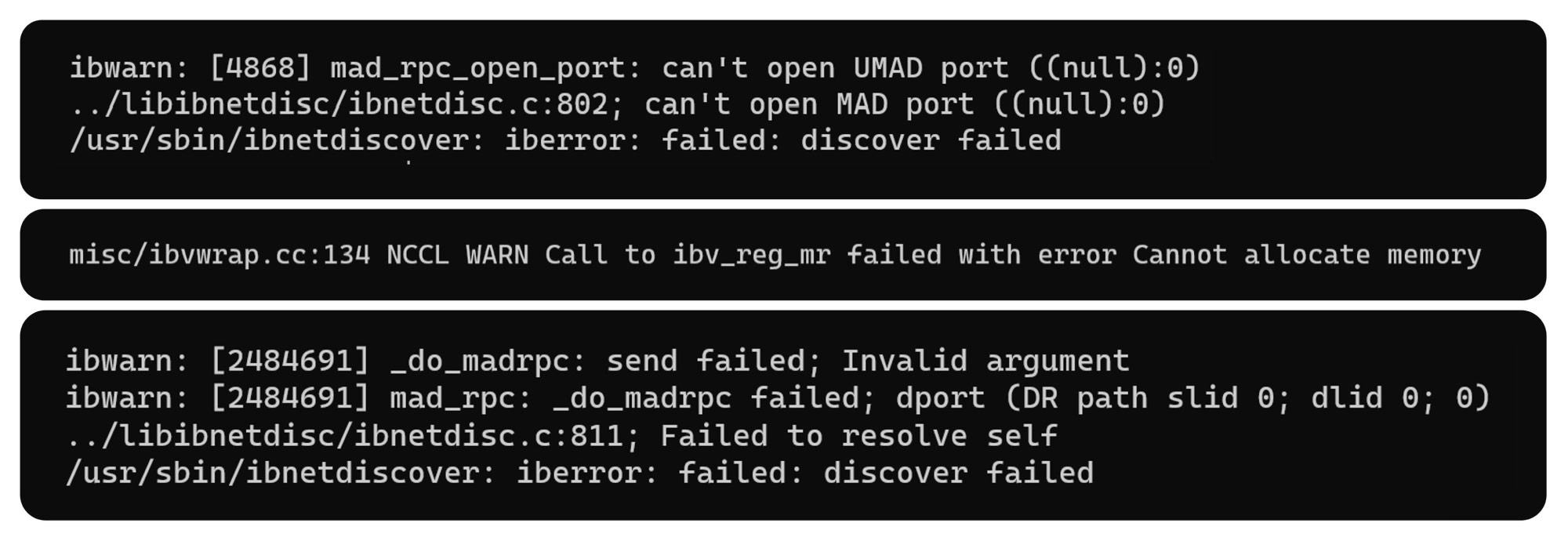
Some of the errors came from the hardware infrastructure; some came from the implementation, particularly from the NCCL itself. Adding to the complexity, both NCCL and the InfiniBand-related libraries often returned vague error messages like the ones above, leaving the team to decipher the issues and come up with fixes based on minimal information.
After the initial problems were solved, Recraft noticed the training process was very slow, operating at an 8x slower rate than in an ideal scenario where the network is not a bottleneck.
Some quick fixes related to the network were implemented by both the Recraft and Nebius engineering teams:
- GPU Direct RDMA (Remote Direct Memory Access) was configured successfully.
- Nebius quickly provided a patch to NCCL.
- The team at Recraft had to recompile specific packages like PyTorch, which rely on a static NCCL build.
These adjustments made the network 4x faster, leading to a ~6x increase in training speed.
However, the team soon faced another hurdle. Training sessions began to stall unpredictably, either immediately after commencement or days into the process, with various, still unclear errors from NCCL adding to the confusion. These issues highlighted the crucial role of dedicated solution architects on the cloud platform side. Nebius has stepped in here, addressing problems from different sources — as it turned out, mostly related to hardware. For example, network links were flapping or overheating.
In parallel, to automatically register hardware failures, Recraft has introduced an alert system rooted in two fundamental ideas:
- Training jobs send out “heartbeats” at each training step.
- If the “heartbeat” is not received within a set interval, an alert is sent to Slack, clearly indicating something has happened.
Results
Thanks to these concerted efforts, Recraft overcame hardware and configuration challenges and also achieved remarkable stability in their system. The company trained a text-to-image foundation model that demonstrates the state-of-the-art performance compared to all major competitors. A model’s results were determined by achieving over 50% preference on PartiPrompts benchmark, with Recraft’s wins highlighted in green:
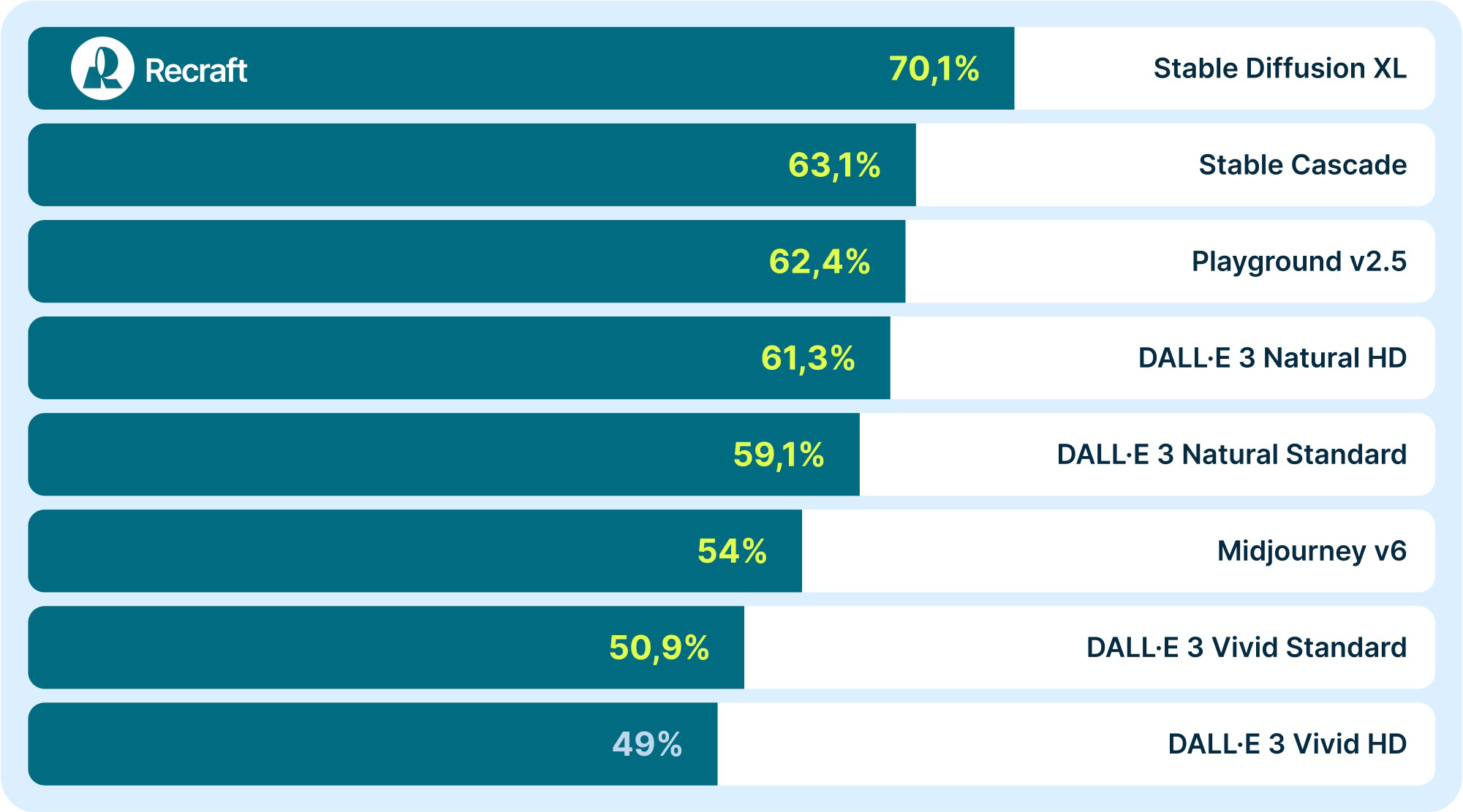
Key takeaways
- Proper alerts, if possible, must be implemented in advance to help identify ongoing issues.
- Logging should always be enabled to issues maximize troubleshooting capabilities.
- To successfully train large models, it’s not just the amount of hardware that matters but also the ability to manage it — both when hardware issues must be addressed and when the training is implemented efficiently.
- Due to the many potential problems, dedicated solution architects, support and direct communication with cloud engineers are extremely important.
Nebius services used
Compute Cloud
Providing secure and scalable computing capacity for hosting and testing your projects. GPU-accelerated instances use top-of-line NVIDIA GPUs.
Object Storage
Secure, scalable and cost-effective cloud object storage. Store, easily access, share and manage large amounts of unstructured data.
Managed Service for Kubernetes®
Providing a streamlined Kubernetes deployment and management experience. You can count on scalability, security and automated updates.
More exciting stories

Unum
In our field, partnerships that harness complementary strengths can drive significant breakthroughs. Such is the case with the collaboration between Nebius AI and Unum, an AI research lab known for developing compact and efficient AI models.

Dubformer
Dubformer is a secure AI dubbing and end-to-end localization solution that guarantees broadcast quality in over 70 languages. The company manages two of its most resource-intensive tasks on Nebius AI: ML itself and the deployment of models.