
Optimizing inference with math: TheStage AI and its framework

The premise
The inference market has grown so significantly that inefficiencies between revenue and inference costs have emerged. TheStage AI’s solution is designed to close this gap.
![]()
TheStage AI is an inference optimization platform that enables users to reduce GPU costs, identify bottlenecks in DNN inference, speed up neural networks using state-of-the-art algorithms, and deploy final models.

During the latter half of the 2010s, the team that would eventually form the core of TheStage AI was working at Huawei, focusing on optimizing inference in mobile phones and other edge devices. A well-known example is the rapid processing of freshly taken photos using on-device models, but there are many more local models and use cases at play. Today, these solutions are used in dozens of Huawei smartphones.
In 2023, TheStage AI CEO and co-founder Kirill Solodskikh and other co-founders published a paper on neural network optimization for inference at the prestigious CVPR 2023 conference. This paper was recognized as an award candidate, and some of its ideas became the inspiration of TheStage AI’s current business.
Technology in a nutshell
TheStage AI now offers a control panel and an inference simulator aimed at reducing costs for larger models. Interestingly, technologies from edge devices can and should be reused for this purpose, and vice versa. TheStage AI’s product is called ANNA — it’s an automatic neural network analyzer and optimizer. The best analogy would be an image optimizer, where you adjust a slider to get the best quality at a given JPEG file size.
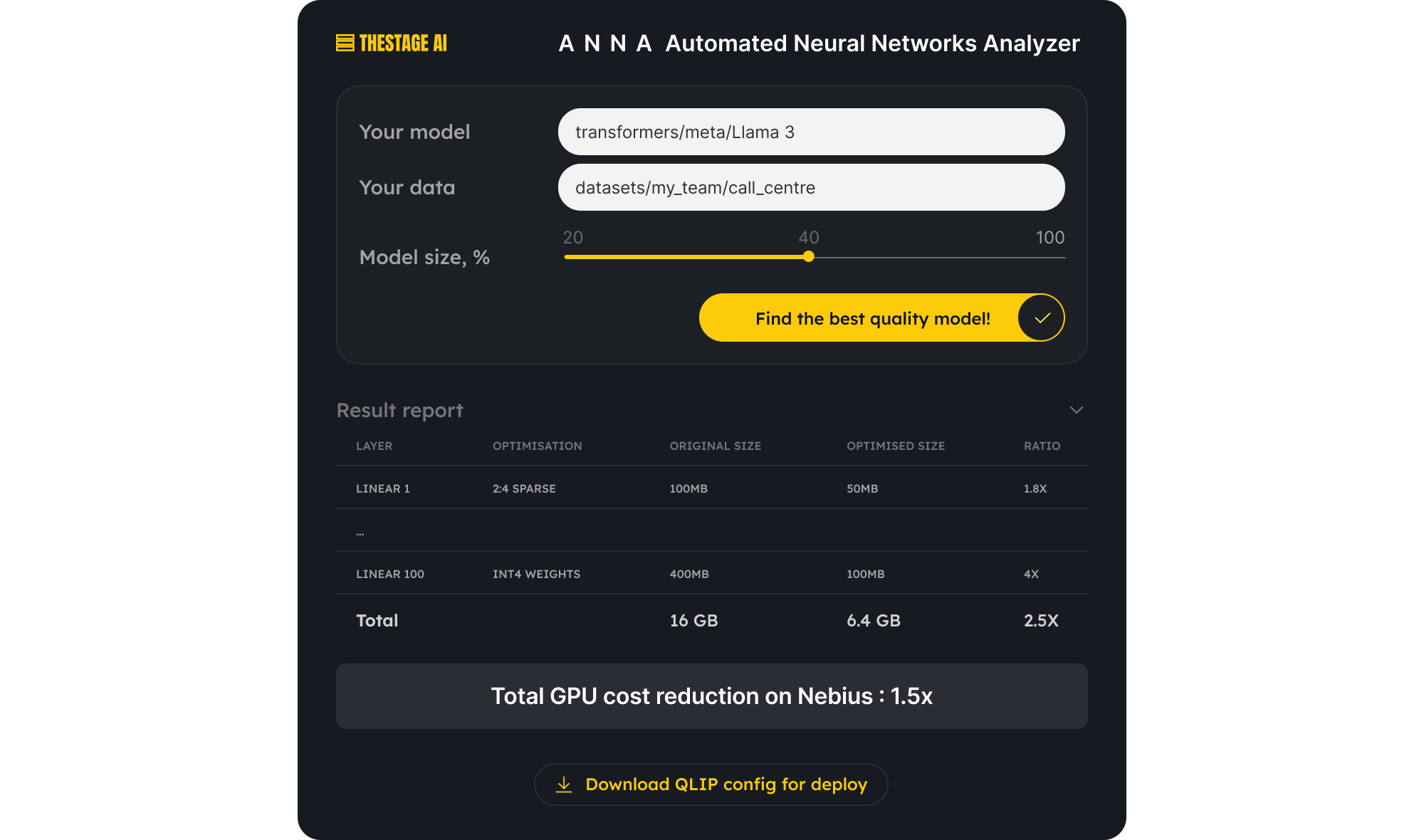
In the case of neural networks, inference time is predefined. These in-house technologies are based on strict mathematical solutions, a mathematical framework described in the CVPR research and other papers by TheStageAI. You upload a model and data, then the system analyzes it without getting into the specifics of the network’s functions, highlighting available optimizations. You choose the desired size and inference time. The significance here lies in the fact that multiple different models can be produced — each with varying cost/quality ratios. These options are optimal in that the cost decreases with minimal quality degradation. The system constructs a curve specifically for your data, guaranteed by the framework, resulting in a smaller model with minimal loss of quality.
On a slightly less abstract level, each type of NVIDIA Tensor Core chip has a unique set of hardware instructions for low-level acceleration. There are well-known techniques for using these instructions, such as reducing a network’s representation from 32 bits to 8 or even 4 bits, which automatically speeds up processing. However, this often comes at the cost of reduced network quality.
TheStage AI’s innovation lies in creating algorithms that respect the specifics of different hardware while maintaining quality. The team uses an intermediate instruction format that can be properly mapped to different chips, not just those from NVIDIA.
TheStage AI team is most excited when hardware manufacturers support as many of these accelerators as possible on their side, as this makes it easier to design algorithms that take advantage of them. It’s much simpler than trying to write low-level code tailored to specific hardware.
Integration with Nebius
The integration with us as a cloud provider works as follows: TheStage AI offers model creators the ability to evaluate cost/quality ratios by uploading the original model to Nebius’s infrastructure. After the model undergoes a series of optimizations, TheStage AI provides a one-click solution to deploy the final model in the same infrastructure. It’s a kind of referral program.
Before choosing Nebius, TheStage AI tested several providers in search of the most stable training environment. Thanks to the efforts of Nebius’ cloud architects and in-house LLM R&D, our solutions ensured uninterrupted GPU operation right out of the box, without requiring any special MLOps competencies from TheStage AI. Nebius proved to be the most stable platform among those tested.
Although TheStage AI’s experimental process does not require GPUs to be utilized 24/7, the team always keeps at least several H100 nodes available. This allows immediate deployment whenever an experiment needs to be conducted. For AI researchers, not being distracted by preliminary environment setup during a project is more important than the small extra costs this incurs.
Let us build pipelines of the same complexity for you
Our dedicated solution architects will examine all your specific requirements and build a solution tailored specifically for you.
In-house research
TheStage AI also uses Nebius’ infrastructure to develop new methods for accelerating inference. One way the company interacts with clients is by having TheStage AI researchers work with a user’s model on Nebius’ VMs, fine-tune the model, and then return it to the developers for further use with the previously described automation.
One of the recent foundational models handled by TheStage AI required running relatively low-resource evaluations and experiments to optimize. There was no need to train the entire model from scratch, so only one GPU node provided by Nebius was used. Similar actions with Praktika’s models allowed the company to triple the GPU cost savings.
Gradually, these manual and undocumented actions will become less necessary. Ideally, users will simply be able to upload their model and a small amount of typical data, where quality must be consistently high.
Competition
TheStage AI does face competition, but most of it comes from internal teams within major players like Qualcomm, Huawei, and Google. This is partly because, until recently, there weren’t many specialists in the market focusing on inference optimization. As mentioned earlier, this field has primarily been of interest to, and continues to interest, edge device manufacturers.
In a sense, systems like Kubernetes also help with this task — for instance, they optimize client costs by automatically shutting down unnecessary VMs. But TheStage AI’s strength lies in the fact that, according to the company, the primary GPU cost reduction comes from analyzing and optimizing the model itself. Kubernetes can improve GPU utilization and scale it automatically, but even with autoscaling, DNN inference requires a significant amount of resources. If you want, say, a fourfold improvement, you need to work on the model itself.
Next stages
TheStage AI’s clients currently include the previously mentioned Praktika and several other companies. All of them are developing their own models and looking for ways to optimize them, making TheStage AI’s offering highly relevant.
The company’s next step is to enter the industrial market. This will require learning to work with models of up to 500 billion parameters, which will necessitate organizing research in a multi-host setup with an InfiniBand network. Overall, fine-tuning such large models on a single host is simply not cost-effective.
Looking ahead, TheStage AI believes that the next race will involve implementing the acceleration and optimization technologies currently embedded in their platform at a lower level — for instance, deploying them as part of data center solutions.
Nebius services used
Compute Cloud
Providing secure and scalable computing capacity for hosting and testing your projects. GPU-accelerated instances use top-of-line NVIDIA GPUs.
Virtual Private Cloud
Providing a private and secure connection between Nebius resources in your virtual network and the Internet.
More exciting stories

LIMS
How well can LLMs abstract problem-solving rules and how to test such ability? A research by the London Institute for Mathematical Sciences, conducted using our infrastructure, helps to understand the causes of LLM imperfections.

Recraft
Recraft, recently funded in a round led by Khosla Ventures and former GitHub CEO Nat Friedman, is the first generative AI model built for designers. Featuring 20 billion parameters, the model was trained from scratch on Nebius AI.

Krisp
Krisp’s work with us lies in the field of Accent Localization, an AI-powered real-time voice conversion technology that removes the accent from call center agent speech resulting in US-native speech.